Monday, December 29, 2008
"Coaching dla programisty". Ruszł program pilotażowy
O postępach w rozwijaniu rozwijaniu umiejętności dowiesz się z bloga jednego z uczestników programu: Rafała 0.
Monday, December 22, 2008
Wzorce projektowe - Fabryki. Rysunkowy tutorial
Kreacyjne wzorce projektowe dostarczają programistą szeregu metod pozwalających na sprawne zarządzanie tworzeniem obiektów w systemie. W tutorialu omawiam kilka z nich, prezentując strukturę w postaci diagramów UML, implementację oraz obszary zastosowań.
Jeśli chcesz przypomnieć sobie jak czytać diagramy UML w odniesieniu do kodu Java przeczytaj najpierw wcześniejsze tutoriale:














Friday, December 12, 2008
Light? heavy?
Sporo już powiedziano o relacji pomiędzy Spring a EJB. Jedni twierdzili, że to konkurencyjne rozwiązania, inni zgodzili się, że wzajemnie się uzupełniają. Moje prywatne zdanie jest takie, że Spring wyrósł na obrzydzeniu do EJB2.x i jego podstawowymi zaletami były: nieinwazyjność, lekkość, elastyczność i coś co nazywam sobie lepkością czyli umiejętność integracji i "przylepiania się" do istniejących rozwiązań. Pojawienie się EJB3 trochę rozmyło granice. Oto bowiem dostaliśmy eleganckie rozwiązanie korporacyjne z niezależną od kontenera częścią do trwałego przechowywania danych i innymi bajerami. Co prawda całość była nieco w tyle, za rozwiązaniami z community, ale aura standardu słodziła niedogodności. W takiej sytuacji moim zdaniem pomiędzy Spring a EJB istniały 2 zasadnicze:
- EJB wymaga osobnego kontenera, Spring nie
- jeśli używasz EJB to bierzesz całą technologię, cało wielgachną maszynerię którą oferuje, w Springu bierzesz tyle ile potrzebujesz
Tuesday, December 9, 2008
Weekendowe Warsztaty: Wzorce Projektowe w Paraktyce
Zapraszam na „Weekendowe Warsztaty: Wzorce Projektowe w
Paraktyce".
Każdy uczestnik ma swój komputer (notebook), aby realizować ćwiczenia.
Osią warsztatów jest projekt, który jest sukcesywnie rozwijany -
dodawane są nowe funkcjonalności. Rozbudowa systemu jest pretekstem do
wprowadzania kolejnych wzorców.
Warsztaty mają charakter praktyczny i ostatecznie prowadzą do stworzenia
systemu opartego o wzorce, zachowując pragmatyzm przy ich użyciu. Przede
wszystkim stawiamy na podkreślenie aspektu współpracy między wzorcami,
gdyż największa ich siła ujawnia się dopiero wtedy.
ZOBACZ PROGRAM
http://www.bnsit.pl/files/Wzorce_projektowe_java_i_refaktoring.pdf
KIEDY?: 13, 14 grudnia br.
CZAS TRWANIA: 2 x 8 godzin (sobota, niedziela), od 9 do 17
GDZIE?: W centrum Łodzi; wybór konkretnej sali zależy od ilości uczestników
CZEGO POTRZEBUJESZ?:
* Notebook z kartą Wi-Fi
* Zapału i chęci do poznania czegoś nowego
JAK SIĘ ZGŁOSIĆ?:
* przesłać mail na adres bnsit@bnsit.pl z tematem WARSZTATY
* wpłacić zaliczkę (do piątku 12 grudnia br.) w wysokości 100zł na
konto mBank 12 1140 2004 0000 3902 5596 2724, w tytule przelewu proszę
wpisać swoje imię i nazwisko; dane adresowe firmy znajdziesz w stopce maila
* pozostała część opłaty wnoszona jest przed rozpoczęciem zajęć w sobotę
* w przypadku, gdy nie zgłosi się wystarczająca ilość uczestników, aby
uruchomić szkolenie, otrzymasz zwrot zaliczki w ciągu 3 dni roboczych
TWOJA INWESTYCJA: 800 zł
Na dodatkowe pytania odpowie Michał Bartyzel m.bartyzel{{{orangutan}}}bnsit.pl
Paraktyce".
Każdy uczestnik ma swój komputer (notebook), aby realizować ćwiczenia.
Osią warsztatów jest projekt, który jest sukcesywnie rozwijany -
dodawane są nowe funkcjonalności. Rozbudowa systemu jest pretekstem do
wprowadzania kolejnych wzorców.
Warsztaty mają charakter praktyczny i ostatecznie prowadzą do stworzenia
systemu opartego o wzorce, zachowując pragmatyzm przy ich użyciu. Przede
wszystkim stawiamy na podkreślenie aspektu współpracy między wzorcami,
gdyż największa ich siła ujawnia się dopiero wtedy.
ZOBACZ PROGRAM
http://www.bnsit.pl/files/Wzorce_projektowe_java_i_refaktoring.pdf
KIEDY?: 13, 14 grudnia br.
CZAS TRWANIA: 2 x 8 godzin (sobota, niedziela), od 9 do 17
GDZIE?: W centrum Łodzi; wybór konkretnej sali zależy od ilości uczestników
CZEGO POTRZEBUJESZ?:
* Notebook z kartą Wi-Fi
* Zapału i chęci do poznania czegoś nowego
JAK SIĘ ZGŁOSIĆ?:
* przesłać mail na adres bnsit@bnsit.pl z tematem WARSZTATY
* wpłacić zaliczkę (do piątku 12 grudnia br.) w wysokości 100zł na
konto mBank 12 1140 2004 0000 3902 5596 2724, w tytule przelewu proszę
wpisać swoje imię i nazwisko; dane adresowe firmy znajdziesz w stopce maila
* pozostała część opłaty wnoszona jest przed rozpoczęciem zajęć w sobotę
* w przypadku, gdy nie zgłosi się wystarczająca ilość uczestników, aby
uruchomić szkolenie, otrzymasz zwrot zaliczki w ciągu 3 dni roboczych
TWOJA INWESTYCJA: 800 zł
Na dodatkowe pytania odpowie Michał Bartyzel m.bartyzel{{{orangutan}}}bnsit.pl
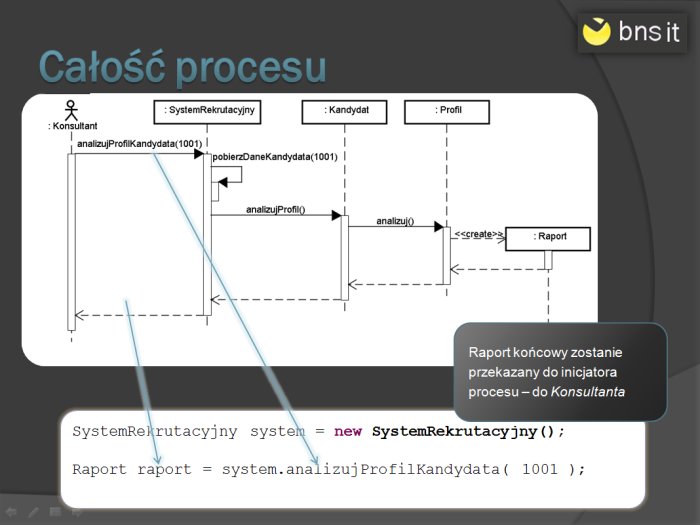
Java i UML - Diagram sekwencji. Rysunkowy tutorial
Diagram sekwencji jest, obok diagramu klas, najczęściej używanym diagramem UML. Pozwala ma modelowanie dynamicznych aspektów systemu.
W artykule zamieszczam bardzo zwięzły rysunkowy tutorial, obrazujący sposób korzystania z diagramu sekwencji. Dodatkowo dodałem przykłady pokazujące relację pomiędzy diagramem, a kodem w języku Java.






Tuesday, December 2, 2008
Ad.pilotażowego programu "Coaching dla programisty"
W związku z pytaniami zamieszczam więcej szczegółowych informacji nt. programu.
CEL: Praktyczne zweryfikowanie hipotezy: "Każdy może stać się dobrym programistą"
ADRESACI: Osoby, które:
* znają język Java
* posiadają niewielkie doświadczenie w pracy w tym języku (np.: język Java poznany na studiach, certyfikat SCJP, samodzielna nauka języka, pisanie programów na zaliczenia albo jako hobby)
* chcą pracować jako programiści Java/JEE
* potrafią prezcyzyjnie określić swój cel zawodowy w perspektywnie najbliższych 2 lat
KOSZT: bns it nie pobiera opłaty od uczestników programu
ZOBOWIĄZNIA UCZESTNIKA:
* ukończenie programu
* systematyczna praca
* prowadzenie bloga programistycznego, na którym uczestnik będzie regularnie opisywał swoje doświadczenia, spostrzeżenia, porady dla innych, itp.
ZOBOWIĄZANIA BNS IT:
* zapewnienie wykwalifikowanego trenera
* prowadzenie zajęć i ocenianie postępów
JAK APLIKOWAĆ:
* przysłać zgłoszenie na adres m.bartyzel {maupeczka} bnsit.pl
* w treści maila proszę umieścić frazę [COACHING]
* do zgłoszenia proszę dołączyć kod źródłowy programu napisanego w języku Java (np. program, z którego jesteś najbardziej dumny/a albo taki, który napiszesz specjalnie dla mnie:))
* do zgłoszenia proszę dołączyć linki do 3 ofert pracy, którymi jesteś zainteresowany
* do zgłoszenia proszę dołączyć informację: w jakich miastach rozważasz pracę jako programista, kiedy orientacyjnie planujesz zacząć pracę
* na każde zgłoszenie odpowiemy do 20 grudnia
* zastrzegamy sobie prawo do przyjęcia tylko wybranych kandydatów/kandydatek
FORMA ZAJĘĆ:
* zajęcia odbywają się zdalnie za pośrdednictwem komunikatora
* sesje odbywają się 1 lub 2 razy w tygodniu w odzinach
ustalonych indywidualnie z trenerem
* ogólny plan zajęć można przedstawić następująco:
- sformułowanie celu do osiągniecia
- stworzenie harmonogramu prac
- systematyczna praca nad przygotowaniem się do osiągnięcia postawionego celu
- osiągnięcie celu
- koniec uczestnictwa w programie
CZAS TRWANIA:
* zależy od czestnika oraz postawionego celu
* szacunkowo można zakładać od 3 miesięcy w górę
DALSZE PERSPEKTYWY:
* Po pozytywnym ukończeniu programu "Coaching dla programisty":
- osiągniesz postawiony przez siebie cel
* Do poniższych rzeczy się nie zobowiązujemy, ale też nie wykluczamy, że:
- być może przygotujemy Cię do rozmowy kwalifikacyjnej
- być może polecimy Ci firmę rekruterską
- być może być może zorganizujemy Ci spoktanie z potencjalnym pracodawcą
- być może zaproponujemy Ci pracę w jednym z projektów projektów prowadzonych przez nas
- być może...:)
i jeszcze krótka notatka dot. przykładowego kodu, o który proszę:
1. To nie musi być ukończony i działający program. Chciałbym się zorientować co do sposobu pisania
2. Interfejs użytkownika jest dla mnie na chwilę obecną najmniej ważny
3. Przykładowe aplikacje:
* System ankietujący - ma umożliwiać przygotowanie, wysłanie i zebranie odpowiedzi na pytania zawarte w ankiecie
* System aukcyjny - ma umożliwiać przeprowadzanie aukcji internetowych
A TERAZ UWAGA! Ponieważ wiem, że programiści mają tendencję do perfekcjonizmu i wykonanie zadanie mogło by kogoś pochłonąć na kilka najbliższych lat:) proszę ustawić sobie czasomierz i przesłać mi tyle ile da się napisać W CIĄGU 36 GODZIN(oczywiście nie trzeba siedzieć przed komputerem 3 dni z rzędu:) można rozłożyć pracę na tydzień albo 2)
CEL: Praktyczne zweryfikowanie hipotezy: "Każdy może stać się dobrym programistą"
ADRESACI: Osoby, które:
* znają język Java
* posiadają niewielkie doświadczenie w pracy w tym języku (np.: język Java poznany na studiach, certyfikat SCJP, samodzielna nauka języka, pisanie programów na zaliczenia albo jako hobby)
* chcą pracować jako programiści Java/JEE
* potrafią prezcyzyjnie określić swój cel zawodowy w perspektywnie najbliższych 2 lat
KOSZT: bns it nie pobiera opłaty od uczestników programu
ZOBOWIĄZNIA UCZESTNIKA:
* ukończenie programu
* systematyczna praca
* prowadzenie bloga programistycznego, na którym uczestnik będzie regularnie opisywał swoje doświadczenia, spostrzeżenia, porady dla innych, itp.
ZOBOWIĄZANIA BNS IT:
* zapewnienie wykwalifikowanego trenera
* prowadzenie zajęć i ocenianie postępów
JAK APLIKOWAĆ:
* przysłać zgłoszenie na adres m.bartyzel {maupeczka} bnsit.pl
* w treści maila proszę umieścić frazę [COACHING]
* do zgłoszenia proszę dołączyć kod źródłowy programu napisanego w języku Java (np. program, z którego jesteś najbardziej dumny/a albo taki, który napiszesz specjalnie dla mnie:))
* do zgłoszenia proszę dołączyć linki do 3 ofert pracy, którymi jesteś zainteresowany
* do zgłoszenia proszę dołączyć informację: w jakich miastach rozważasz pracę jako programista, kiedy orientacyjnie planujesz zacząć pracę
* na każde zgłoszenie odpowiemy do 20 grudnia
* zastrzegamy sobie prawo do przyjęcia tylko wybranych kandydatów/kandydatek
FORMA ZAJĘĆ:
* zajęcia odbywają się zdalnie za pośrdednictwem komunikatora
* sesje odbywają się 1 lub 2 razy w tygodniu w odzinach
ustalonych indywidualnie z trenerem
* ogólny plan zajęć można przedstawić następująco:
- sformułowanie celu do osiągniecia
- stworzenie harmonogramu prac
- systematyczna praca nad przygotowaniem się do osiągnięcia postawionego celu
- osiągnięcie celu
- koniec uczestnictwa w programie
CZAS TRWANIA:
* zależy od czestnika oraz postawionego celu
* szacunkowo można zakładać od 3 miesięcy w górę
DALSZE PERSPEKTYWY:
* Po pozytywnym ukończeniu programu "Coaching dla programisty":
- osiągniesz postawiony przez siebie cel
* Do poniższych rzeczy się nie zobowiązujemy, ale też nie wykluczamy, że:
- być może przygotujemy Cię do rozmowy kwalifikacyjnej
- być może polecimy Ci firmę rekruterską
- być może być może zorganizujemy Ci spoktanie z potencjalnym pracodawcą
- być może zaproponujemy Ci pracę w jednym z projektów projektów prowadzonych przez nas
- być może...:)
i jeszcze krótka notatka dot. przykładowego kodu, o który proszę:
1. To nie musi być ukończony i działający program. Chciałbym się zorientować co do sposobu pisania
2. Interfejs użytkownika jest dla mnie na chwilę obecną najmniej ważny
3. Przykładowe aplikacje:
* System ankietujący - ma umożliwiać przygotowanie, wysłanie i zebranie odpowiedzi na pytania zawarte w ankiecie
* System aukcyjny - ma umożliwiać przeprowadzanie aukcji internetowych
A TERAZ UWAGA! Ponieważ wiem, że programiści mają tendencję do perfekcjonizmu i wykonanie zadanie mogło by kogoś pochłonąć na kilka najbliższych lat:) proszę ustawić sobie czasomierz i przesłać mi tyle ile da się napisać W CIĄGU 36 GODZIN(oczywiście nie trzeba siedzieć przed komputerem 3 dni z rzędu:) można rozłożyć pracę na tydzień albo 2)
Friday, November 28, 2008
Zdobądź wymarzoną pracę jako programista/projektant Java/JEE!
Jeśli marzysz o programowaniu,
Jeśli chcesz stać się ekspertem,
Jeśli stale przeglądasz oferty pracy dla programistów
ale
Twoje doświadczenie nie jest wystarczające,
Nie wiesz od czego zacząć,
Przytłacza cię mnogość wymagań w ofertach pracy.
Weź udział w pilotażowym programie Coachig dla programisty. Jeśli dołączysz do programu, zostanie ci przydzielony trener, który podczas indywidualnej pracy z tobą wprowadzi cię w tajniki programowania.
W ciągu kilku miesięcy możesz zostać świetnym programistą i dostać wymarzoną pracę. Przy pomocy trenera sformułujesz cel, który osiągniesz. Czy masz odwagę marzyć...?
U podstaw programu leży przekonanie, że każdy może stać się świetnym programistą.
Stawiamy tylko dwa wymagania:
Ile to kosztuje? 0 zł (słownie: zero zł)
Twój kontakt dot. pilotażowego programu Coaching dla programisty:
Michał Bartyzel
m.bartyzel {{{maupeczka}}} bnsit.pl
+48 503 062 421
Jeśli chcesz stać się ekspertem,
Jeśli stale przeglądasz oferty pracy dla programistów
ale
Twoje doświadczenie nie jest wystarczające,
Nie wiesz od czego zacząć,
Przytłacza cię mnogość wymagań w ofertach pracy.
Weź udział w pilotażowym programie Coachig dla programisty. Jeśli dołączysz do programu, zostanie ci przydzielony trener, który podczas indywidualnej pracy z tobą wprowadzi cię w tajniki programowania.
W ciągu kilku miesięcy możesz zostać świetnym programistą i dostać wymarzoną pracę. Przy pomocy trenera sformułujesz cel, który osiągniesz. Czy masz odwagę marzyć...?
U podstaw programu leży przekonanie, że każdy może stać się świetnym programistą.
Stawiamy tylko dwa wymagania:
- znajomość języka Java (np. wyniesione ze studiów)
- umiejętność systematycznej pracy
Ile to kosztuje? 0 zł (słownie: zero zł)
Twój kontakt dot. pilotażowego programu Coaching dla programisty:
Michał Bartyzel
m.bartyzel {{{maupeczka}}} bnsit.pl
+48 503 062 421
Thursday, November 6, 2008
Język wzorców
Przewrotnie nadałem temu wpisowi tytuł nawiązujący do książki Christophera Alexandra, gdyż od niego zaczęła się ta cała zabawa i chyba już nigdy się nie skończy.
Trudno powiedzieć czy Alexander odkrył naturę powtarzalności czy też tylko uświadomił ludziom to, co czynili od zawsze.
Architektura oprogramowania
Jak na złość koncept powtarzalnych wzorców zyskał największy posłuch wśród inżynierów oprogramowania. Gdy się zastanowić, to są ku temu ważkie powody. Po pierwsze znakomita większość projektów programistycznych przekracza budżet i/lub założone ramy czasowe. Po drugie tworząc milion razy ten sam system można to zrobić na milion różnych sposobów. Naturalnie powstaje pytanie: który ze sposobów jest najlepszy? Bez wahania można odpowiedzieć, że ten który najlepiej spełnia założone kryteria będące w tym przypadku funkcją oceny produktu. Utożsamienie wspomnianej funkcji oceny oprogramowania z, tylko i wyłącznie, wymaganiami użytkowników jest poważanym uproszczeniem. Rzeczona funkcja ma wiele składowych: wymagania użytkowników, założony koszt, ramy czasowe, oczekiwania każdego z członków zespołu, itd. Jedne z nich są specyfikowane jawnie, inne manifestowane zupełnie nieświadomie. Mamy zatem pewne kryterium ewaluacji sposobu programowania: końcowy produkt ma być optymalny ze względu na przyjętą funkcję oceny.
Wzorce projektowe
Szansę na optymalizację funkcji oceny oprogramowania dostrzeżono właśnie w konceptach Christophera Alexandra. Założenia były proste: wiele systemów jest do siebie podobnych, podobieństwo dotyczy różnych poziomów abstrakcji i różnych części systemu. Dodatkowo systemy tworzone są za pomocą języka programowania. Stąd pytanie: czy istnieją takie konstrukcje językowe, które w optymalny sposób rozwiązują problemy związane z programowaniem?
Wspomniane problemy dotyczą sposobu w jaki współpracują obiekty w systemie w celu realizacji określonego zdania. (Część zagadnień opisałem w artykule Organizowanie logiki biznesowej.) W 1995 światło dzienne ujrzała książka Design Patterns katalogująca 23 wzorce projektowe dotyczących inżynierii oprogramowania. Niezwykle ważną rzeczą, prócz samych wzorców, którą wniosła wspomniana publikacja, był aparat pojęciowy umożliwiający rozpoznawanie oraz klasyfikowanie nowych pojawiających się wzorców projektowych. Od tego momentu nastąpiła gwałtowna eksploracja tego tematu przez różnych autorów.
Design Patterns została napisana przez czterech autorów i przyjęło się określać ich jako Gang of Four (GoF), natomiast wzorce przez nich skatalogowane jako Wzorce GoF.
Ich charakterystyczną cechą jest, że dotyczą konstrukcji programistycznych używanych do poprawy jakość tworzonego kodu. Wzorce te dotyczą współpracy obiektów w obrębie jednego systemu.
Umiejętne posługiwanie się tymi wzorcami jest absolutnym minimum kompetencji programisty i bazą dzięki której może on efektywnie korzystać z kolejnych technologii. Wzorce GoF są podstawą piramidy, na której opiera się praca i rozwój programisty. Istnieje możliwość wzięcia udziału w Weekendowych Warsztatach z Wzorców GoF, o których wspominałem w poprzednim wpisie.
Klienci stawiali przed programistami coraz większe wymagania. Systemy informatyczne musiały mieć coraz większą funkcjonalność, stawały się coraz większe. Dało to impuls do rozwoju technologii takich jak J2EE czy .NET. Technologie dostarczają wiele możliwości, czasem zbyt wiele,...technologie bywają niedoskonałe. W przypadku J2EE te niedoskonałości i problemy z użytkowaniem spowodowały powstawanie wzorców projektowych w odniesieniu do tej konkretnej technologii, czego egzemplifikacją stała się przełomowa publikacja Core J2EE Patterns.
Z drugiej strony skala systemów informatycznych, niezależnie od użytej technologii rodziła problemy, których nie rozwiązywały klasyczne Wzorce GoF (GoF, jak pamiętamy, dotyczyły przede wszystkim efektywnej współpracy obiektów pomiędzy sobą w obrębie systemu). Zastosowanie Wzorców GoF w dużym systemie, rzeczywiście ułatwiało pracę i czyniło go bardziej elastycznym, lecz już sama jego rozległość wymagała dodatkowego podejścia - podejścia globalnego, podejścia od strony architektury całego systemu. System miał wykonywać pewne zadania, prezentować dane użytkownikowi i trwale przechowywać wyniki swoich działań. Rozwinęły się: koncepcja warstw w systemie informatycznym oraz pomysły na udostępnianie danych klientom oraz na ich trwałe przechowywanie. Klasyką w tym obszarze jest publikacja Martina Fowlera Patterns of Enterprise Application Architecture, w której autor opisuje wzorce projektowe w aplikacjach klasy enterprise. Pozycja ta daje globalny pogląd na architekturę systemów informatycznych. Wzorce tam opisywane, na własny użytek i dla odróżnienia od GoF, nazywam Wzorcami Architektonicznymi. Warto nadmienić, że Martin Fowler przy gotowuje kolejną publikację na temat Wzorców Architektonicznych. Nie wiadomo kiedy się ona ukaże, jednak z postępem prac można zapoznać się na blogu Fowlera.
Problemy związane z architekturą aplikacji, z użytkowaniem technologii J2EE sprowokowały co najmniej trzy bardzo wartościowe następstwa. Po pierwsze: "stworzyły" środowisko sprzyjające rozwojowi wzorców projektowych. Po drugie: jako implementacja konkretnych Wzorców Architektonicznych powstały frameworki takie jak: Struts, Hibernate, JDO, Spring Framework, WebWork, iBatis i wiele innych. Po trzecie: w konsekwencji popularności frameworków rozpoczął się proces standaryzacyjny JCP, który zaowocował specyfikacją JEE5.
Dalszy rozwój systemów informatycznych uświadomił wszystkim zaangażowanym, że żadna z istniejących technologii jest w jakiś szczególny sposób uprzywilejowana. Jakkolwiek by nie argumentować każda będzie miała swoich zwolenników i przeciwników. Można się z tym poglądem nie zgadzać, ale nie sposób zaprzeczyć, że istnieje jego namacalna konsekwencja: w strukturze informatycznej przedsiębiorstwa działają systemy różnego typu stworzone w różnych technologiach. I choć najbardziej popularne rozwiązania dostarczają sposobów na obsługę całego infrastruktury informatycznej, to jednak każde przedsiębiorstwo ma swoją historię i nikt przy zdrowych zmysłach nie będzie zmieniał sprawnie działającego systemu tylko dlatego, że został napisany w Fortranie a nie w Javie.
Zatem każdy nowy system musi sprawnie komunikować się z istniejącą infrastrukturą. Wymaganie to spowodowało odkrywanie wzorców dotyczących integracji systemów informatycznych. Tę gałąź wzorców projektowych nazywam Wzorcami Integracyjnymi, a jako programową publikację można podać Enterprise Integration Patterns napisaną przez Gregora Hohpe'a i Bobbyego Woolfa.
Poszukiwanie pewnej powtarzalności w tworzeniu systemów informatycznych, mające na celu optymalizowanie określonej wcześniej funkcji oceny, pojawia się na każdym etapie złożoności nie zależnie od tego, czy jest to oprogramowanie desktopowe czy system obsługujący wielką korporację.
Okazuje się, że stosowanie konstrukcji architektonicznych to jedna część układanki. Pracując w różnych projektach programiści wypracowali swego rodzaju wiedzę plemienną, która pomaga im w pracy. Zaznaczam, że nie chodzi tutaj o wzorce projektowe, które rozwiązują konkretne problemy, chodzi raczej o sposób posługiwania się wzorcami w możliwie efektywny sposób.
Odkrycie strategii postępowania programistów wiąże się ze spostrzeżeniem, iż kod źródłowy jest częściej czytany niż pisany. Zatem sposób pisania kodu, konwencje, standardy, w tym sposób używania wzorców projektowych jest kolejnym obszarem, w którym można poszukiwać powtarzalności.
Doświadczony programista przechodząc z projektu do projektu będzie przenosił pewne pomocne nawyki mające ułatwić mu tworzenie oprogramowania. Dalej, doświadczony lider będzie dbał o to, aby uspójniać te nawyki wśród zespołu. Po co? Celem jest tu efektywna komunikacja. Jeden programista sprawniej pracuje posługując się sposobem kodowania który zna, zespół sprawnie pracuje posługując się tym samym stylem kodowania, nowa osoba w projekcie łatwiej wdroży się do zadań jeśli będzie mogła czytać kod wg pewnych, z góry określonych, zasad.
Wzorce wyodrębnione na tym poziomie zostały zaprezentowane przez Kenta Becka w książce
Implementation Patterns.
Wzorce Implementacyjne to kolejny kamień milowy w poszukiwaniu powtarzalnych schematów podczas wytwarzania oprogramowania. Dotyczą one sposobów posługiwania się językiem oraz wzorcami projektowymi, a nie konkretnej architektury oprogramowania. Używając porównania do budownictwa: Wzorce Projektowe mówią jakich cegieł należy używać, Wzorce Implementacyjne wskazują jak najlepiej pchać taczkę.
Dalsza dekompozycja
Richard Dawkins w swojej książce Samolubny gen stawia hipotezę, że rozwój nie jest progresywny lecz ekspansywny. Nie przebiega zgodnie z odgórnie ustalonym planem lecz odbywa się poprzez najlepsze dopasowanie do sytuacji bieżącej. Jednostką rozwoju nie jest istota wysokiego rzędu np. człowiek, lecz najbardziej elementarna jednostka - gen. Gen maksymalizuje swoje korzyści w danej chwili, a rozwój osobników wyższego rzędu jest jedynie skutkiem "samolubnych" zachowań genu.
Zastanawia mnie czy ta sama zasada obowiązuje, jawnie bądź w ukrytej postaci, podczas wytwarzania oprogramowania? Bytem wyższego rzędu jest system informatyczny, lecz kto jest samolubnym genem? Obiekt, czy może...programista? Kto dąży to maksymalizowania swoich korzyści w danej chwili? Dawkinsowy gen zachowuje się samolubnie, gdyż pragnie przetrwać, przekazać swój materiał genetyczny. Rozważając programowanie obiektowe musimy zrezygnować z przypisywania obiektom cech genów, gdyż jest obiekt jest ze swej strony bierny w obszarze replikacji. A zatem programista? Czy programista jest samolubnym genem? Zaznaczam, że nie chodzi to celowe działanie na szkodę, lecz o nieświadomy mechanizm funkcjonowania. Jeśli programista spełnia funkcję genu, to materiałem genetycznym musi być kod, który jest przez niego pisany!
Końcowy produkt jest zatem wypadkową: wymagań klienta, budżetu, ram czasowych oraz samolubności programisty. O ile z zewnątrz, w działaniach objawiających się bezpośrednio użytkownikowi, pierwsze cztery czynniki mają znaczącą rolę, o tyle wewnątrz systemu największe znaczenie ma samolubność programisty. Na czym miałaby ona polegać? Na przekazaniu jak największej ilości swoich koncepcji, rozwiązań, pomysłów do kodu systemu. Z kolei koncepcje te zależą od indywidualnych predyspozycji, umiejętności stosowania Wzorców Projektowych i Implementacyjncych,...humoru, itd. Stąd najkorzystniej dla projektu jest dbać o jakość przekazywanych koncepcji dbając o rozwój programistów.
Wspomniany Chirstopher Alexander w książce Timeless Way of Building przedstawia, podobny w idei, koncept, który nazywa porządkiem naturalnym.
(Przykład za Christopher Alexander czyli w poszukiwaniu doskonałości) Wyobraźmy salę wypełnioną krzesłami w uporządkowany sposób. Chcąc umieścić na sali jak najwięcej osób, można identyczne krzesła ustawić równo w rzędach optymalnie wypełniając salę. Na sali zmieści się wiele osób, ale nie wszystkim będzie wygodnie.
Z drugiej strony można poprosić osoby aby przyszły z własnymi krzesłami i usiadły możliwie najbliżej siebie. W tej sytuacji na sali będą krzesła różnego typu: duże i małe, odległości między nimi będą różne - w zależności od potrzeb siedzących, lecz wszyscy będą się starali, aby na sali zmieściło się najwięcej osób. Takie uporządkowanie Alexander nazywa porządkiem naturalnym. Charakteryzuje się on tym, każda osób ma tyle miejsca ile potrzebuje oraz występuje sprzężenie zwrotne z całością systemu (chęć zmieszczenia jak największej ilości osób). Charakterystyczną cechą porządku naturalnego jest to, że za każdym razem będzie przebiegał według tych samych reguł i za każdym razem efekt końcowy będzie nieco inny od poprzedniego.
W obu przedstawionych koncepcjach kształt ostatecznego systemu jest sterowany przez działania programisty. Alexander dokłada jednak jedną drobną, acz kluczową rzecz: sprzężenie zwrotne.
Można zatem wnioskować, że jeżeli każdy programista ma dokładną świadomość ostatecznego celu, ostatecznego kształtu systemu i dbając przekazywanie własnych koncepcji w kodzie, weźmie pod uwagę to sprzężenie zwrotne, to jakość wytworzonego oprogramowania wzrośnie.
Koncept sprzężenia zwrotnego uwidacznia się w programowaniu między innymi w takich podejściach jak Continuous Integration, Continuous Testing, czy Test-Driven Development. Całość podejścia do wytwarzania oprogramowania wywiedzionego z porządku naturalnego uwidacznia się w metodykach Agile.
Należy podkreślić jednak niezwykle istotną rzecz. We wspomnianym przykładzie nt. porządku naturalnego, to ludzie przynosili własne krzesła i ustawiali je optymalnie do własnych potrzeb, biorąc pod uwagę całość systemu. Również w podejściu Agile ciężar odpowiedzialności przeniesiony został na programistę. Już nie procedury sterują projektem, lecz ludzie. Wymaga to od programisty wiele uwagi, dojrzałości, a przede wszystkim odpowiedzialności. Wymaga również kompetencji innego rodzaju niż biegłość techniczna w stosowaniu określonych technologii, Wzorców Projektowych, czy Implementacyjnych.
Poza kodem źródłowym
W poszukiwaniu powtarzalności podczas wytwarzania oprogramowania przeszliśmy ścieżkę od Wzorców GoF, poprzez Wzorce Architektoniczne, Implementacyjne, aż do powtarzalnych procesów Agile, gdzie programista tworząc kod nieustannie bierze pod uwagę końcowy kształt systemu.
Każdy programista wie, że nauka wymienionych rzeczy zabiera wiele czasu. Moim zdaniem minimum 2 lata, a to i tak w odpowiednich warunkach. Jednym zabiera to wspomniane 2 lata, innym dłużej, a może i krócej, wielu zniechęca się po drodze. Lecz ci, którym się udało zaczęli programować w inny sposób. Jaka jest zatem różnica pomiędzy stanem początkowym, a końcowym w ścieżce rozwoju programisty i gdzie tej różnicy poszukiwać?
Z pewnością różnica nie polega na znajomości wzorców, bo wiedza teoretyczna może nie zmienić się przez ten czas. Ale przecież różnica istniej! Widać ją w sposobie kodowania, w sposobie podejścia do problemu, w jakości wytwarzanego oprogramowania.
Być może chodzi o to, że taki programista czuje programowanie, myśli poprzez wzorce, widzi je i potrafi zastosować w praktyce. Następuje zatem zmiana w sposobie myślenia (o pewnych jej aspektach pisałem w artykule Metaprogramy w tworzeniu oprogramowania).
Skoro programista czujący programowanie ma pewien nowy sposób myślenia, a jest wielu takich programistów, to można wnioskować, że istnieje pewien zbiór sposobów postępowania czy myślenia, charakterystyczny dla tych ludzi. Z pewnością każdy robi to w nieco inny sposób, ale skoro potrafią otrzymywać identyczne wyniki w postaci fantastycznie napisanego kodu, to jest jakaś część wspólna tych strategii. Zatem istnieją pewne powtarzalne wzorce, coś jak najlepsze praktyki skutecznych programistów, które charakteryzują ludzie osiągających sukcesy w naszej branży.
Odkrycie tych wzorców jest moim zdaniem kolejnym wyzwaniem przed inżynierią oprogramowania, kolejnym etapem odkrywania i stosowania optymalnych metod pracy.
Kolejne kroki usprawniania pracy wiodą od udoskonalania narzędzi i metod do rozwoju programisty. Tak już jest, że jakkolwiek skomplikowany by system nie był, w centralnym punkcje i tak znajduje się człowiek.
Wednesday, November 5, 2008
Weekendowe Warsztaty Wzorce Projektowe
Serdecznie zapraszamy na „Warsztaty weekendowe poświęcone wzorcom projektowym”. Jest to oferta specjalna dla użytkowników portalu Goldenline.pl i czytelników mojego bloga i bloga Mariusza. Tej oferty nie znajdziesz na stronie BNS IT!
Warsztaty umożliwiają nabycie praktycznych umiejętności tworzenia aplikacji z użyciem wzorców projektowych w języku Java.
Zobacz program warsztatów
Czego potrzebujesz?
• Notebook z kartą wi-fi
• Zapału, chęci i otwartego umysłu
Twoja inwestycja to jedyne: 800 zł.
Nigdzie nie znajdziesz szkolenia ani warsztatów w takiej cenie i jakości.
Powiedz znajomym.
Gdzie?
Warszawa, 13-14.12.2008
Wrocław, 13-14.12.2008
Kraków, 13-14.12.2008
Kontakt:
m.sieraczkiewicz [[[[[ MAUPA ]]]]]] bnsit.pl
+48 500 189 752
http://www.bnsit.pl
Warsztaty umożliwiają nabycie praktycznych umiejętności tworzenia aplikacji z użyciem wzorców projektowych w języku Java.
Zobacz program warsztatów
Czego potrzebujesz?
• Notebook z kartą wi-fi
• Zapału, chęci i otwartego umysłu
Twoja inwestycja to jedyne: 800 zł.
Nigdzie nie znajdziesz szkolenia ani warsztatów w takiej cenie i jakości.
Powiedz znajomym.
Gdzie?
Warszawa, 13-14.12.2008
Wrocław, 13-14.12.2008
Kraków, 13-14.12.2008
Kontakt:
m.sieraczkiewicz [[[[[ MAUPA ]]]]]] bnsit.pl
+48 500 189 752
http://www.bnsit.pl
Friday, October 31, 2008
Wzorce projektowe: Temporal Object
Gdy zaczynałem poznawać wzorce projektowe punktem wyjścia dla mnie były książki w stylu GoF, blogi, fora, itd. Znajdowałem tam przede wszystkim diagramy UML, oraz banalne przykłady kodu w stylu: fabryka pizzy, szablon algorytmu, budowniczy okienka. Mój kłopot polegał na tym, że chociaż rozumiałem o czym się do mnie pisze, to nie wiedziałem jak zastosować te koncepcje w moim kodzie. Moje projekty związane były np. ze sklepem internetowym lub systemem ankietowym i nijak to się miało do pizzy, algorytmów czy okienek. Brakowało mi przede wszystkim sensownej implementacji wzorca oraz konkretnych wskazówek jak i gdzie go użyć.
Po jakimś czasie zacząłem analizować źródła programów OpenSource takie jak Spring i apache-commons. Sęk w tym, że aby zrozumieć dobrze te projekty trzeba było wzorce projektowe wcześniej znać, a ja dopiero chciałem się ich nauczyć. Sporo mnie kosztowało rozgryzanie tego tematu.
W tej serii artykułów odpowiem choć na część w/w pytań. Będę: omawiał różne wzorce, podawał przykładowe implementacje i podpowiadał gdzie można ich użyć. Jeśli chodzi o sam sposób użycia czyli wprowadzanie wzorca do projektu i wykrywanie potencjalnych miejsc jego zastosowania w projekcie, to ten temat zostanie poruszony w wątku o refaktoringu (w najbliższej przyszłości).
Obiekty z historią
Wyobraźmy sobie, że należy stworzyć model obiektowy, który posłuży do zrealizowania funkcjonalności sklepu (taaa...wiem, że przykład mocno wyświechtany, lecz jakże użyteczny i skoro skojarzenia takie jak Hello world!, foo bar i Team-Member mocno zapadły w umysły rzesz programistów, więc i ja nie będę odstawał i posłużę się dobrze znanym przykładem rzeczonego sklepu).
Centralną klasą modelu będzie obiekt Order. Zakładając, że klient użytkujący sklep może zapisać stan swojego zamówienia, a następnie do niego wrócić, okazuje się, że warto śledzić historię jego...hmmm...niezdecydowania? W przypadku sklepu może być to pomocne np. podczas analizy aktywności klienta, na podstawie której można będzie mu w przyszłości zaproponować nowe produkty i usługi.
Postawiony problem można uogólnić następująco: stan danego obiektu może zmieniać się w czasie i należy zapewnić możliwość śledzenia historii zmian.
W tym miejscu zrób krótką przerwę, weź kartkę i długopis oraz zaproponuj przykładowe rozwiązanie omówionej kwestii.
Już masz? Świetnie, zatem porównaj je z dalszą częścią artykułu.
Temporal Object
Twoje rozwiązanie jest z pewnością wystarczające, lecz posłuchaj o innym, które jest na tyle często eksploatowane przez programistów, zostało określone mianem wzorca projektowego.
Intencją wzorca Temporal Object jest śledzenie zmian w obiekcie i udostępnianie ich na życzenie. Wzorzec ten jest również znany pod nazwami History on Self oraz Version History.
W przykładzie mamy do czynienia obiektem reprezentującym zamówienie. Sformułujmy wymagania co do funkcjonalności:
- usługa pracuje z obiektem zamówienia Order
- zamówienie można dowolnie zmieniać
- historia zmiana ma być śledzona i udostępniana na życzenie
- dla celów raportowych, oprócz bieżących, należy zapamiętywać godzinowe milestones
Spójrzmy na projekt rozwiązania:

Głównym konceptem jest wprowadzenie obiektu OrderVersion, który śledzi zmiany w zamówieni, tzn. dla każdej zmiany tworzony jest nowy obiekt OrderVersion. Sam obiekt klasy Order, z które będą korzystały usługi jest niejako proxy bieżącej wersji zamówienia. Dodatkowo wprowadzona została klasa VersionHistory, której odpowiedzialnością jest zarządzanie historią zamówienia.
Całe piękno tego rozwiązania polega na tym, że usłudze udostępniony będzie obiekt Order, który powinien proksować API OrderVersion tyle, że pracuje zawsze na wersji bieżącej. Reszta przetwarzania jest ukryta przed klientem.
Zgodnie z założeniem tej serii artykułów przedstawiam również implementację wzorca.
public class Order implements Serializable {
private Long id;
private VersionHistory versioningHistory = new VersionHistory();
private OrderVersion currentVersion;
public void createNewVersion( String productId,
String productName, Double price ) {
OrderVersion orderVersion = new OrderVersion();
orderVersion.setCustomId( productId );
orderVersion.setName( productName );
orderVersion.setPrice( price );
versioningHistory
.addOrderVersion( orderVersion.getDate(),
orderVersion );
currentVersion = orderVersion;
}
public void setCurrentVersionTo( Date when ) {
currentVersion = versioningHistory.findVersion( when );
}
protected OrderVersion getCurrentVersion() {
return currentVersion;
}
public String getCustomId() {
return getCurrentVersion().getCustomId();
}
public void setCustomId( String customId ) {
getCurrentVersion().setCustomId( customId );
}
//delegacje reszty getterów i setterów
}
public class VersionHistory implements Serializable {
private Map orderVersions
= new HashMap();
private List orderHourMilestones
= new ArrayList();
public OrderVersion findVersion( Date date ) {
return orderVersions.get( date );
}
public void addOrderVersion( Date date, OrderVersion version ) {
orderVersions.put( date , version );
}
public void createHourMilestone() {
//...
}
}
public class OrderVersion implements Serializable {
private Long id;
private String customId;
private String name;
private Double price;
private Date date;
public OrderVersion() {
this.date = Utils.getNow();
}
}
//gettery i settery
A co z persystencją?
Kolejny problem, o który można potknąć się podczas nauki wzorców to kwestia związana z trwałym przechowywaniem danych. O ile w języku obiektowym można napisać niemal wszystko, również w bazie danych można stworzyć dowolnie złożone rozwiązanie to jednak sklejenie tego razem czasem nastręcza kłopotów. Dlatego, aby opis wzorca był kompletny zajmijmy się teraz trwałym przechowywaniem danych w relacyjnej bazie danych.
Domyślnie, używając dostarczycieli persystencji dla JPA, przyjmowana jest zasada, że jeden obiekt jest mapowany do jednej tabeli w bazie danych. Moim zdaniem przyjęcie takiej arbitralnej zasady prowadzi do bałaganu w bazie danych oraz do jej „niewyważenia”. Niewyważenie rozumiem jako sytuację, gdzie poszczególne tabele przechowują nieproporcjonalnie dużą ilość danych, np. jedna tabela ma 2 kolumny oraz 10 wierszy, natomiast inna 20 kolumn i 10000 wierszy. Taka sytuacja w moim mniemaniu daje przesłanki do zastanowienia się, czy ta mała tabela jest potrzebna. Być może można znajdujące się w niej dane umieścić jako dodatkową kolumnę i innej tabeli i w ten sposób uprość zapytania SQL pracujące na bazie. Zaznaczam, że to moje prywatne zdanie.
Wykorzystując mapowania JPA umieścimy strukturę obiektową w dwóch tabelach: orders – przechowującej zamówienia oraz orders_versions – przechowującą wersje poszczególnych zamówień.
Schemat bazy danych będzie wyglądał następująco:

Wiersze z orders identyfikują poszczególne zamówienia oraz wskazują na jego bieżącą wersję. Natomiast wiersze z orders_versions przechowują dane na temat danej wersji.
Dodatkowo każda wersja wskazuje na zamówienie do którego należy oraz, jeśli jest godzinowym milestonem, to wskazuje na właściciela. Na poziomie obiektowym pomiędzy obiektami Order oraz VersionHistory występuje relacja 1:1, zatem wiersze z orders identyfikują również obiekt VersionHistory. Z tego względu orders_versions posiada dodatkowe wskazanie na orders w postaci klucza ref_order_hour_milestone, określające, że dana wersja należy do historii wersji danego zamówienia.
Odpowiednie mapowania JPA wyglądają następująco:
@Entity @Table( name = "orders" )
@NamedQuery( name="Order.findAll", query="from Order" )
public class Order implements Serializable {
@Id
@GeneratedValue( strategy=GenerationType.AUTO )
private Long id;
@Embedded
private VersionHistory versioningHistory = new VersionHistory();
@OneToOne
@JoinColumn(name="ref_current_version")
private OrderVersion currentVersion;
}
@Embeddable
public class VersionHistory implements Serializable {
@OneToMany(cascade=CascadeType.ALL)
@MapKey( name="date" )
@JoinColumn( name="ref_order_history" )
private Map orderVersions
= new HashMap();
@OneToMany
@JoinColumn( name="ref_order_hour_milestone" )
private List orderHourMilestones
= new ArrayList();
}
@Entity @Table( name = "orders_versions" )
public class OrderVersion implements Serializable {
@Id
@GeneratedValue( strategy=GenerationType.AUTO )
private Long id;
@Column( name="custom_id" )
private String customId;
private String name;
private Double price;
private Date date;
}
Jak można zauważyć pomiędzy tabelami ordersa orders_versions występuje powiązanie dwukierunkowe.
Na wstępie tego rozdziału wspominałem o dbaniu o optymalność zapytań. Przeprowadziłem test i zapis jednego zamówienia z trzema wersjami powoduje wykonanie na bazie następujących zapytań SQL:
Hibernate: insert into orders (ref_current_version) values (?)
Hibernate: insert into orders_versions (custom_id, date, name, price) values (?, ?, ?, ?)
Hibernate: insert into orders_versions (custom_id, date, name, price) values (?, ?, ?, ?)
Hibernate: insert into orders_versions (custom_id, date, name, price) values (?, ?, ?, ?)
Hibernate: update orders set ref_current_version=? where id=?
Hibernate: update orders_versions set ref_order_hour_milestone=? where id=?
Hibernate: update orders_versions set ref_order_history=? where id=?
Hibernate: update orders_versions set ref_order_history=? where id=?
Hibernate: update orders_versions set ref_order_history=? where id=?
Zmieńmy jedna nieco schemat bazy danych przenosząc powiązanie zamówienia z jego bieżącą wersją do tabeli orders_versions. Rysunek poniżej:

Zmiana na w mapowaniach jest bardzo niewielka:
//...
public class Order implements Serializable {
//...
@OneToOne(mappedBy="parentOrder")
private OrderVersion currentVersion;
//...
public void createNewVersion( String productId, String productName,
Double price ) {
//..
orderVersion.setParentOrder( this );
}
}
//..
public class OrderVersion implements Serializable {
//..
@OneToOne
@JoinColumn(name="ref_order")
private Order parentOrder;
//..
}
Zestaw zapytań tym razem wygenerowany przez Hibernate wygląda następująco:
Hibernate: insert into orders values ( )
Hibernate: insert into orders_versions (custom_id, date, name, ref_order, price) values (?, ?, ?, ?, ?)
Hibernate: insert into orders_versions (custom_id, date, name, ref_order, price) values (?, ?, ?, ?, ?)
Hibernate: insert into orders_versions (custom_id, date, name, ref_order, price) values (?, ?, ?, ?, ?)
Hibernate: update orders_versions set ref_order_hour_milestone=? where id=?
Hibernate: update orders_versions set ref_order_history=? where id=?
Hibernate: update orders_versions set ref_order_history=? where id=?
Hibernate: update orders_versions set ref_order_history=? where id=?
Zatem mamy o jedno zapytanie mniej. Czy to dużo? Trudno powiedzieć, aczkolwiek na każde tysiąc zapisów zamówienia do bazy danych mamy tysiąc zapytań mniej...
Podsumowując
Wzorca Temporal Object można użyć jeśli występuje potrzeba śledzenia i zapamiętywania zmian w modelu obiektowym. Używając narzędzi O\RM o trwałego zapisu danych, nie dajmy się zwieść iluzji, że programista może zapomnieć o bazie danych. Jeśli mamy na uwadze wydajność należy o tym pamiętać, zwłaszcza wtedy, gdy większość narzędzi ukrywa przed programistą złożoność swoich działań.
Kompletny kod źródłowy omawianego rozwiązania znajdziesz na blogu, którego adres widoczny jest na stronie tytułowej artykułu. W projekcie zostały użyte mapowania JPA, Hibernate jako dostarczyciel persystencji oraz baza danych MySQL
Wednesday, October 29, 2008
Uwaga na Immutable + JPA
Ostatnio użyłem wzorca Immutable w tradycyjnej implementacji
Po zmapowaniu klasy adnotacjami JPA sporo głowiłem się dlaczego dostaję albo zbyt wiele wierszy w bazie albo wyjątek z informacją, że nastąpiła próba zapisu obiektu transient...rzut oka na powyższy kod wyjaśnia sprawę ;) ech...
public class Team {
public Member getMember() {
return new Member( this.member );
}
}
Po zmapowaniu klasy adnotacjami JPA sporo głowiłem się dlaczego dostaję albo zbyt wiele wierszy w bazie albo wyjątek z informacją, że nastąpiła próba zapisu obiektu transient...rzut oka na powyższy kod wyjaśnia sprawę ;) ech...
Tuesday, October 28, 2008
Strzeż się ludzi, którzy są pewni tego, że mają rację!
Programista, architekt, bazodanowiec, temaleader...cokolwiek człowiek by nie robił, z biegiem czasu się specjalizuje, z biegiem czasu staje się ekspertem. I to chyba jest bardzo niebezpieczne...
Zbyt łatwo zdarza się nam powiedzieć do siebie samego: "Ok, już wszystko umiem". Kiedy przyjdzie Ci do głowy takie zdanie wiedz, że już po tobie! Twoja kariera, kimkolwiek byś nie był, właśnie rozpoczęła powolny lecz konsekwentny ruch w dół, czy raczej w tył.
Powyższe, wypowiedziane na głos lub choć wewnętrznie zadeklarowane, stwierdzenie automatycznie zamyka na dalszy rozwój, gdyż zakłada, że on się zakończył. Świat się rozwija, technologia się rozwija i zatrzymanie się w miejscu faktycznie oznacza cofanie się.
Profesjonalizm można poznać po tym, że osoba pozostaje otwarta. Otwarta na to, że każdego dnia może nauczyć się czegoś nowego, że może nauczyć się czegoś od młodszego kolegi właśnie przyjętego do pracy, od podwładnego, od kogoś kogo uważa za mniej kompetentnego od siebie, że może nauczyć się czegoś od swojego ucznia. Tylko ta postawa gwarantuje możliwość ciągłego doskonalenia się. Oto jest sens słynnego Wiem, że nic nie wiem!
Zbyt łatwo zdarza się nam powiedzieć do siebie samego: "Ok, już wszystko umiem". Kiedy przyjdzie Ci do głowy takie zdanie wiedz, że już po tobie! Twoja kariera, kimkolwiek byś nie był, właśnie rozpoczęła powolny lecz konsekwentny ruch w dół, czy raczej w tył.
Powyższe, wypowiedziane na głos lub choć wewnętrznie zadeklarowane, stwierdzenie automatycznie zamyka na dalszy rozwój, gdyż zakłada, że on się zakończył. Świat się rozwija, technologia się rozwija i zatrzymanie się w miejscu faktycznie oznacza cofanie się.
Profesjonalizm można poznać po tym, że osoba pozostaje otwarta. Otwarta na to, że każdego dnia może nauczyć się czegoś nowego, że może nauczyć się czegoś od młodszego kolegi właśnie przyjętego do pracy, od podwładnego, od kogoś kogo uważa za mniej kompetentnego od siebie, że może nauczyć się czegoś od swojego ucznia. Tylko ta postawa gwarantuje możliwość ciągłego doskonalenia się. Oto jest sens słynnego Wiem, że nic nie wiem!
Thursday, October 2, 2008
Organizowanie logiki biznesowej
Chris Richardson, w książce Pojo in Action podaje kilka decyzji, które musi podjąć projektant systemu enterprise w Jawie. Jednym z wyborów przed którym rzeczony projektant stoi dotyczy sposobu w jaki zorganizowana jest logika biznesowa. Autor nazywa to wyborem pomiędzy podejściem proceduralnym a obiektowym. Rzecz w tym, by wybrać jeden z trzech opisanych przez Martina Fowlera wzorców. Choć Richardson podaje pewne kryteria, to jednak operuje na pojęciach wybitnie nieostrych typu: duże projekty, małe projekty, skomplikowana logika, niewiele logiki. W artykule chciałbym przyjrzeć się problemowi i podać bardziej namacalne kryteria wyboru.
(Czytelnik niezaznajomiony z wzorcami enterprise znajdzie zwięzłe charakterystyki na końcu artykułu; po szczegóły odsyłam do bliki Martina Fowlera, rozdział Domain Logic Patterns.
Bez obawy! Nikt nie zmusza Cię do cofnięcia się w świat języków proceduralnych, nie w tym rzecz...Istotę problemu można sformułować następująco: Powstało wymaganie biznesowe, aby napisać system robiący COŚ TAM. Jak się do tego zabrać, aby uczynić zadość oczekiwaniom klienta i jednocześnie włożyć to wysiłek odpowiedni do natury rzeczy. Wiadomo, że klient chciałby jak najwyższą jakość za jak najniższą ceną, natomiast dostawca chce dostarczyć najniższą dopuszczalną jakość za jak najwyższą cenę. Słowem, kwestia jest poważna.
Klasyczne podejście obiektowe każe nam zbudować obiektowy model dziedziny problemu charakteryzujący się współpracującymi pomiędzy sobą obiektami, z których każdy charakteryzuje się swoim stanem oraz zachowaniem. Obiekty będą współpracować ze sobą odzwierciedlając swój stan w bazie danych oraz w interfejsie użytkownika w taki sposób, aby zrealizować zdefiniowane przez niego wymagania.
W podejściu proceduralnym nie będziemy modelować rzeczywistości, nie będziemy modelować dziedziny problemu. W tym podejściu każemy bazie danych krok po kroku zapamiętać pewne dane, każemy interfejsowi użytkownika wprost wypisać pewne dane tak, aby w konsekwencji użytkownik dostał to, co chciał. Skąd wiemy co chciał? Chciał to, co definiują use cases.
Jak przełożą się powyższe decyzje na prace programisty? Np. tak, że w pierwszym przypadku zaprzęgniemy do działania Spring Framework, JSF i Hibernate albo EJB i resztę a drugim zdecydujemy się na PHP. Albo jeśli lubimy Jawę, to w drugim przypadku weźmiemy Tomcata, Struts2 i nie zważając na to co nam mówią o warstwach i odpowiedzialnościach, zaimplementujemy całą logikę w akcjach (tu właśnie mogą być pomocne Transaction Script lub Table Module, sprawdź w jaki sposób:))
Zauważmy, że działania użytkownika w każdym, nawet najbardziej skomplikowanym systemie, w ostatecznym rozrachunku sprowadzają się odpowiedniej sekwencji operacji CRUD. Tak, końcowym rezultatem interakcji pomiędzy obiektami jest zmiana stanu bazy danych. Można zatem twierdzić, że każdą usługę systemu zdefiniowaną poprzez use case można zastąpić skończoną ilością operacji elementarnych CRUD. Ot i istota całego problemu.
Kwestia wyboru pomiędzy podejściem obiektowym a proceduralnym sprowadza się do rozstrzygnięcia jaka jest relacja pomiędzy usługą systemu a operacjami elementarnymi.
Jeśli jest to przełożenie 1:1 np. sklep internetowy, katalog książek, itp, gdzie działania użytkowników sprowadzają się właściwie do operacji CRUD to opłaca się użyć podejścia proceduralnego.
Jeśli mamy do czynienia np. z aplikacją kadr i płac, bankiem czy obsługą giełdy to usługa systemu może mieć przełożenie na setki albo tysiące operacji elementarnych. W takim przypadku stworzenie rzetelnego modelu dziedziny ułatwi panowanie nad rozwojem projektu. Skorzystamy też z dobrodziejstwa wielu frameworków, które ułatwiają pracę. Pamiętajmy, że w konsekwencji i tak ostatecznym rezultatem będzie zestaw CRUDów z tą różnicą, że nie będziemy zmuszeni tworzyć go samodzielnie, dzięki modelowi obiektowemu oraz frameworkom zatrzymamy się na wysokim poziomie abstrakcji.
Wiem, że pominąłem kilka istotnych aspektów takich jak bezpieczeństwo, transakcyjnośc itd. Koncentrowałem się tylko na organizowaniu logiki biznesowej.
Transaction Script - w podejściu proceduralnym pozwala na ujecie w całość wielu operacji, które muszą być wykonane w jednej transakcji
Domain Model - podejście obiektowe charakteryzuje się tworzenie modelu obiektowego dziedziny problemu
Table Module - w podejściu proceduralnym jest czymś pośrednim pomiedzy Transaction Script a Domain Model, pozwala na skupienie logiki biznesowej w okół danych, na których logika pracuje
(Czytelnik niezaznajomiony z wzorcami enterprise znajdzie zwięzłe charakterystyki na końcu artykułu; po szczegóły odsyłam do bliki Martina Fowlera, rozdział Domain Logic Patterns.
Proceduralnie czy obiektowo?
Bez obawy! Nikt nie zmusza Cię do cofnięcia się w świat języków proceduralnych, nie w tym rzecz...Istotę problemu można sformułować następująco: Powstało wymaganie biznesowe, aby napisać system robiący COŚ TAM. Jak się do tego zabrać, aby uczynić zadość oczekiwaniom klienta i jednocześnie włożyć to wysiłek odpowiedni do natury rzeczy. Wiadomo, że klient chciałby jak najwyższą jakość za jak najniższą ceną, natomiast dostawca chce dostarczyć najniższą dopuszczalną jakość za jak najwyższą cenę. Słowem, kwestia jest poważna.
Klasyczne podejście obiektowe każe nam zbudować obiektowy model dziedziny problemu charakteryzujący się współpracującymi pomiędzy sobą obiektami, z których każdy charakteryzuje się swoim stanem oraz zachowaniem. Obiekty będą współpracować ze sobą odzwierciedlając swój stan w bazie danych oraz w interfejsie użytkownika w taki sposób, aby zrealizować zdefiniowane przez niego wymagania.
W podejściu proceduralnym nie będziemy modelować rzeczywistości, nie będziemy modelować dziedziny problemu. W tym podejściu każemy bazie danych krok po kroku zapamiętać pewne dane, każemy interfejsowi użytkownika wprost wypisać pewne dane tak, aby w konsekwencji użytkownik dostał to, co chciał. Skąd wiemy co chciał? Chciał to, co definiują use cases.
Jak przełożą się powyższe decyzje na prace programisty? Np. tak, że w pierwszym przypadku zaprzęgniemy do działania Spring Framework, JSF i Hibernate albo EJB i resztę a drugim zdecydujemy się na PHP. Albo jeśli lubimy Jawę, to w drugim przypadku weźmiemy Tomcata, Struts2 i nie zważając na to co nam mówią o warstwach i odpowiedzialnościach, zaimplementujemy całą logikę w akcjach (tu właśnie mogą być pomocne Transaction Script lub Table Module, sprawdź w jaki sposób:))
Zauważmy, że działania użytkownika w każdym, nawet najbardziej skomplikowanym systemie, w ostatecznym rozrachunku sprowadzają się odpowiedniej sekwencji operacji CRUD. Tak, końcowym rezultatem interakcji pomiędzy obiektami jest zmiana stanu bazy danych. Można zatem twierdzić, że każdą usługę systemu zdefiniowaną poprzez use case można zastąpić skończoną ilością operacji elementarnych CRUD. Ot i istota całego problemu.
Kwestia wyboru pomiędzy podejściem obiektowym a proceduralnym sprowadza się do rozstrzygnięcia jaka jest relacja pomiędzy usługą systemu a operacjami elementarnymi.
Jeśli jest to przełożenie 1:1 np. sklep internetowy, katalog książek, itp, gdzie działania użytkowników sprowadzają się właściwie do operacji CRUD to opłaca się użyć podejścia proceduralnego.
Jeśli mamy do czynienia np. z aplikacją kadr i płac, bankiem czy obsługą giełdy to usługa systemu może mieć przełożenie na setki albo tysiące operacji elementarnych. W takim przypadku stworzenie rzetelnego modelu dziedziny ułatwi panowanie nad rozwojem projektu. Skorzystamy też z dobrodziejstwa wielu frameworków, które ułatwiają pracę. Pamiętajmy, że w konsekwencji i tak ostatecznym rezultatem będzie zestaw CRUDów z tą różnicą, że nie będziemy zmuszeni tworzyć go samodzielnie, dzięki modelowi obiektowemu oraz frameworkom zatrzymamy się na wysokim poziomie abstrakcji.
Wiem, że pominąłem kilka istotnych aspektów takich jak bezpieczeństwo, transakcyjnośc itd. Koncentrowałem się tylko na organizowaniu logiki biznesowej.
Transaction Script - w podejściu proceduralnym pozwala na ujecie w całość wielu operacji, które muszą być wykonane w jednej transakcji
Domain Model - podejście obiektowe charakteryzuje się tworzenie modelu obiektowego dziedziny problemu
Table Module - w podejściu proceduralnym jest czymś pośrednim pomiedzy Transaction Script a Domain Model, pozwala na skupienie logiki biznesowej w okół danych, na których logika pracuje
Tuesday, July 22, 2008
Jakieś to takie skomplikowane...
Ostatnio miałem trochę do czynienia z narzędziem PowerDesigner. Ogólnie rzecz ujmując jest to narzędzie do modelowania...
Próbując określić odpowiedzialność tego narzędzia doszedłem do wniosku, że jest to narzędzie, które wychodząc od procesu biznesowego, pozwala w zrozumiały dla wszystkich (od dołu aż do góry korporacyjnej hierarchii) sposób opisać to, co dzieje się w biznesie, wspomóc analizę tegoż oraz, jeśli zajdzie taka potrzeba, doprowadzić do zaprojektowania stosownych narzędzi informatycznych, począwszy od wstępnych wymagań, na szkielecie systemu z wykorzystaniem konkretnych technologii skończywszy, uff!
Rzeczą, która od razu rzuciła mi się w oczy, to ogrom możliwości tego narzędzia. Użytkownik może stworzyć różnego rodzaju modele, diagramy i zależności między nimi. Jako (zaznaczam: początkującemu) użytkownikowi brakowało mi procesu, który wskazywałby kierunek prac. PowerDesigner nie wspiera żadnej metodyki, więc w zasadzie nie wiadomo co należy robić. I mimo, że można wszystko, to i tak nie wiadomo co...
Projektanci narzędzia z pewnością mieli pomysł na jego używanie. Przynajmniej ja gorąco w to wierzę. Aczkolwiek odniosłem wrażenie, że Sybase próbuje forsować jakieś własne podejście do modelowania, za nic sobie mając przyzwyczajenia analityków. Owszem, PowerDesigner wspiera co tylko może wspierać, ale odpowiedzialności poszczególnych składowych nachodzą na siebie. Tego właśnie mi brakowało! - dokładnie zdefiniowanych odpowiedzialności poszczególnych modelów.
Skoro 95% tego, co można zrobić w PowerDesigner, da się zrealizować za pomocą UML, to po co mi narzędzie za $7000?
Trzeba uczciwie przyznać, że po głębszym przyjrzeniu się narzędzie szokuje możliwościami, lecz nie wychodzenie na przeciw przyzwyczajeniom użytkowników sprawia, że próbują oni używać programu na swój własnny sposób, niezgodny z pomysłem projektantów. Oczywiście powoduje to frustrację, a interfejs użytkownika czyni nieergonomicznym do granic możliwości.
Wiele narzędzi przekonało mnie, że próby generowania kodu "z automatu" kończą się źle. Nie inaczej i w tym przypadku. Totalna kaszana, choć wierzę, że intencje były dobre.
PowerDesigner sprawia wrażenia programu rozwijanego przez grupę fantastycznych, ale kompletnie oderwanych od rzeczywistości, programistów.
Mówią, że "jeśli coś jest do wszystkiego, to jest do niczego". Odkryłem, że to bzdura i daleko idące uogólnienie. Takie, na przykład, koło, dźwignia albo
klin. Używane są wszędzie i do wszystkiego, ale nikt im nie zarzuca, że są nieprzydatne.
Otóż i esencja mojego odkrycia: jeśli coś jest wystarczająco proste, może być "do wszystkiego" albo inaczej złożoność narzędzia/koncepcji/rozwiązania jest odwrotnie proporcjonalna do zakresu jego stosowalności.
Gdyby zatem Sybase, zamiast gigantycznego all-in-one, wypuścił zestaw narzędzi o określonej specjalizacji, które dodatkowo świetnie ze sobą współpracują, to miałby u mnie lepsze noty:)
Dobrym przykładem jest pakiet MS Office. Pomiając indywidualne upodobania, mamy klarowną sytuację: Word - piszemy, Excel - liczmy, PowerPoint - prezentujemy, Outlook - organizujemy, Binder - i to jest genialne, spinamy wszystko razem ale tak, że narzędzie nie zatracają własnej indywidualności. Dla użytkownika jest w miarę jasne co ma zrobić, aby uzyskać określony efekt.
Ilu diagramów UML najczęściej używasz? Ja 2 - klas i sekwencji. A ilu elementów z tych diagramów najczęściej korzystasz? Ja z co najwyżej 10. Duch Pareto nie śpi, co? UML, z początku fajny, ale w miarę rozrastania się i usztywniania zrobił się beee. To musi pęknąć, już pęka. Powstają mutacje w stylu Robustness Diagrams, które wybierają z UML tylko to, co jest naprawdę niezbędne do określonego celu.
Osobiście traktuję UML jako zbiór sugestii odnośnie modelowania Używam piktogramów, ale konkretne zasady traktuje raczej luźno. Jestem zdania, że jeśli zespół jednoznacznie rozumie notację, to jest to ok. Nawet jeśli jest to notacja nieformalna.
Myślę, że jeśli chodzi o projekty (nie tylko IT) będziemy świadkami następujących przemian:
Próbując określić odpowiedzialność tego narzędzia doszedłem do wniosku, że jest to narzędzie, które wychodząc od procesu biznesowego, pozwala w zrozumiały dla wszystkich (od dołu aż do góry korporacyjnej hierarchii) sposób opisać to, co dzieje się w biznesie, wspomóc analizę tegoż oraz, jeśli zajdzie taka potrzeba, doprowadzić do zaprojektowania stosownych narzędzi informatycznych, począwszy od wstępnych wymagań, na szkielecie systemu z wykorzystaniem konkretnych technologii skończywszy, uff!
Po pierwsze: zgubiłem się w strukturze
Rzeczą, która od razu rzuciła mi się w oczy, to ogrom możliwości tego narzędzia. Użytkownik może stworzyć różnego rodzaju modele, diagramy i zależności między nimi. Jako (zaznaczam: początkującemu) użytkownikowi brakowało mi procesu, który wskazywałby kierunek prac. PowerDesigner nie wspiera żadnej metodyki, więc w zasadzie nie wiadomo co należy robić. I mimo, że można wszystko, to i tak nie wiadomo co...
Po drugie: "Na przekór czasom i ludziom wbrew..."
Projektanci narzędzia z pewnością mieli pomysł na jego używanie. Przynajmniej ja gorąco w to wierzę. Aczkolwiek odniosłem wrażenie, że Sybase próbuje forsować jakieś własne podejście do modelowania, za nic sobie mając przyzwyczajenia analityków. Owszem, PowerDesigner wspiera co tylko może wspierać, ale odpowiedzialności poszczególnych składowych nachodzą na siebie. Tego właśnie mi brakowało! - dokładnie zdefiniowanych odpowiedzialności poszczególnych modelów.
Skoro 95% tego, co można zrobić w PowerDesigner, da się zrealizować za pomocą UML, to po co mi narzędzie za $7000?
Trzeba uczciwie przyznać, że po głębszym przyjrzeniu się narzędzie szokuje możliwościami, lecz nie wychodzenie na przeciw przyzwyczajeniom użytkowników sprawia, że próbują oni używać programu na swój własnny sposób, niezgodny z pomysłem projektantów. Oczywiście powoduje to frustrację, a interfejs użytkownika czyni nieergonomicznym do granic możliwości.
Wiele narzędzi przekonało mnie, że próby generowania kodu "z automatu" kończą się źle. Nie inaczej i w tym przypadku. Totalna kaszana, choć wierzę, że intencje były dobre.
PowerDesigner sprawia wrażenia programu rozwijanego przez grupę fantastycznych, ale kompletnie oderwanych od rzeczywistości, programistów.
Po trzecie: Narzędzie do wszystkiego
Mówią, że "jeśli coś jest do wszystkiego, to jest do niczego". Odkryłem, że to bzdura i daleko idące uogólnienie. Takie, na przykład, koło, dźwignia albo
klin. Używane są wszędzie i do wszystkiego, ale nikt im nie zarzuca, że są nieprzydatne.
Otóż i esencja mojego odkrycia: jeśli coś jest wystarczająco proste, może być "do wszystkiego" albo inaczej złożoność narzędzia/koncepcji/rozwiązania jest odwrotnie proporcjonalna do zakresu jego stosowalności.
Gdyby zatem Sybase, zamiast gigantycznego all-in-one, wypuścił zestaw narzędzi o określonej specjalizacji, które dodatkowo świetnie ze sobą współpracują, to miałby u mnie lepsze noty:)
Dobrym przykładem jest pakiet MS Office. Pomiając indywidualne upodobania, mamy klarowną sytuację: Word - piszemy, Excel - liczmy, PowerPoint - prezentujemy, Outlook - organizujemy, Binder - i to jest genialne, spinamy wszystko razem ale tak, że narzędzie nie zatracają własnej indywidualności. Dla użytkownika jest w miarę jasne co ma zrobić, aby uzyskać określony efekt.
A teraz objadę sobie UMLa
Ilu diagramów UML najczęściej używasz? Ja 2 - klas i sekwencji. A ilu elementów z tych diagramów najczęściej korzystasz? Ja z co najwyżej 10. Duch Pareto nie śpi, co? UML, z początku fajny, ale w miarę rozrastania się i usztywniania zrobił się beee. To musi pęknąć, już pęka. Powstają mutacje w stylu Robustness Diagrams, które wybierają z UML tylko to, co jest naprawdę niezbędne do określonego celu.
Osobiście traktuję UML jako zbiór sugestii odnośnie modelowania Używam piktogramów, ale konkretne zasady traktuje raczej luźno. Jestem zdania, że jeśli zespół jednoznacznie rozumie notację, to jest to ok. Nawet jeśli jest to notacja nieformalna.
Więc czego bym tak naprawdę chciał?
Myślę, że jeśli chodzi o projekty (nie tylko IT) będziemy świadkami następujących przemian:
- centralizacja na rzecz decentralizacji i współpracy
- szansą na ogarnięcie coraz to bardziej złożonych projektów jest podzielenie ich na mniejsze kawałki; brzmi trywialnie...coraz trudniej centralnie sterować ogromnymi przedsięwzięciami programistycznymi, zatem należy zrezygnować (pozornego) kontrolowania sytuacji i bardziej polegać na współpracy niewielkich, wyspecjalizowanych zespołów programistycznych; zamiast na dokładne modele, należy postawić na zaufanie i na kompetentnych ludzi
- ustrukturyzowanie na rzecz procesów, elementów składowych oraz płaskich relacji
- w miarę rozrostu projektu, utrzymywanie odpowiedniej struktury staje się coraz bardziej pracochłonne; po pewnym czasie nadchodzi moment, w którym dbanie, aby wszystko odbywało się wg wytycznych jest kosztowniejsze niż dodawanie wartości biznesowej do produktu; strukturę mogą zastąpić procesy - łatwiejsze w modyfikacji i bardziej elastyczne oraz elementy składowe wraz z płaskimi relacjami pomiędzy nimi;
Monday, July 21, 2008
TDD: O co właściwie chodzi?
Szczerze mówiąc nie wiem jak jest w polskich firmach z TDD. Wiem, że testy się pisze, pokrycie się bada, ale jak z samym TDD sprawy się mają – pojęcie mam bliskie zeru. Wszak pisanie testów i TDD to nie to samo.
Testy jednostkowe
Wiadomo co to są testy jednostkowe i jak działają – w gruncie rzeczy, chodzi o to, aby rozpocząć testowanie możliwie wcześnie na najbardziej elementarnym poziomie – na poziomie obiektów i ich metod. Co i jak testować – na tym skupię się innym razem. Teraz chodzi mi raczej o wyszczególnienie sytuacji z jakimi można zetknąć się podczas pisania testów jednostkowych.
- Testy dopisywane są po zakończeniu implementacji – cóż, jeśli w projekcie do tej pory testów nie praktykowano, to nie ma innej rady. Trzeba pamiętać tylko o jednej rzeczy: jeśli istniejąca metoda zawiera buga, który jeszcze się nie objawił, to napisany do niej test traktuje go jako poprawne działanie metody. Jest tak właśnie dlatego, że test pisany jest do istniejącej metody, przy założeniu że działa ona poprawnie. Trzeba się więc przygotować na niespodzianki.
- Najpierw pisany jest cały test, a następnie cała implementacja – jest to kłopotliwe ponieważ: trudno jest od razu zaplanować kompletny test dla metody, po implementacji często okazuje się, że nawet jeśli jest ona poprawna i tak otrzymujemy green bar. Często z tego powodu, że pomyłka była w teście. I co wtedy, o zgrozo, się dzieje? Zmieniany jest test, a to przecież to on miał być naszą ostoją i gwarantem poprawności implementacji. Jak się za chwilę przekonamy, testy i implementację piszemy przyrostowo – po kawałku.
- Pisane są zbędne testy w celu podniesienia współczynnika pokrycia – to taki przejaw instynktu samozachowawczego. Narzędzia do badania pokrycia po części wykrywają takie sytuacje. Ocenę tych praktyk pozostawiam Czytelnikowi.
- Wykrycie błędów nie powoduje dodania nowego przypadku testowego – jeśli testy nie ewoluują wraz z kodem, to osłabiana jest tkwiąca w nich siła. Każdy błąd wykryty w kodzie powinien spowodować, że: zostanie dodane nowy przypadek testowy wykrywający dany błąd, a następnie implementacja zostanie poprawiona. Dodanie nowego testu zabezpiecza przed ponownym wystąpieniem danego błędu.
- Test odpowiada klasie tylko z nazwy – czasami, w magiczny sposób, implementacja znacznie oddala się od testów. Dzieje się to zwłaszcza wtedy, gdy programiści nie mają nawyku rozpoczynania programowania od testu, pozornie brak czasu na testowanie, a jednocześnie w projekcie nie istnieje kontrola kodu.
- Zapomina się, że testy również podlegają refaktoringowi oraz wypracowano dla nich stosowne wzorce projektowe – wiadomo, że entropia wzrasta z upływem czasu. Nic dziwnego zatem, jeśli w pewnym momencie kod klasy testującej jest tak obrzydliwy i ciężki, że wcale nie chce się go czytać. Wzorce i refaktoring testów to temat na osobny artykuł.
Filozofia TDD
Całe TDD można zamknąć w powiedzeniu: „Kapitanowi, który nie wie dokąd płynie, każdy wiatr jest na rękę”. TDD stwierdza wprost: najpierw postaw cel, a potem do niego zmierzaj – najpierw test, potem implementacja. Ma to dawać następujące korzyści: tworzony jest tylko niezbędny kod – ten który jest istotny dla osiągnięcia celu, rozwiązanie jest przemyślane, ze względu na konieczność rozpoczynania od testu, TDD wymusza dobry projekt obiektowy, gdyż testowanie kodu luźno traktującego inżynierię oprogramowania, to droga przez mękę. Dodatkowo posiadanie zestawu dobrych testów to rzecz absolutnie konieczna jeśli chce się myśleć o bezpiecznym refaktoringu kodu.
Zatem jeśli najpierw należy napisać test, to jak ma wyglądać cały proces?
Wspomniałem wcześniej, że pisanie kompletnego testu, a następnie kompletnej implementacji nie jest dobrą praktyką. Zatem jak? Otóż, przyrostowo, spiralnie – kawałek testu, kawałek implementacji.
- Napisz fragment testu
- Napisz najprostszy możliwy kod, który spełnia test
- Zrefaktoruj implementację do pożądanego stanu
- Czy implementacja wciąż spełnia test?
- Tak: Jeśli implementacja nie zakończona idź do 1
- Nie: Idź do 3
Powyżej znajduje się ramowy algorytm tworzenia oprogramowanie poprzez TDD. Warto podkreślić istotność punktu 2. Dlaczego piszemy najprostszą możliwą implementację spełniającą test? Aby przekonać się czy test jest poprawny. Dlatego właśnie pisanie kompletnego testu od razu jest niewskazane – trudno jest zweryfikować jego poprawność.
Red-Green-Refactor: przykład Eclipse'a wzięty
Załóżmy, że tworzony jest sklep internetowy. Pierwszą funkcjonalnością, którą warto się zająć jest koszyk, z którego będzie korzystał użytkownik. Zaczniemy od odnajdywania produktów w koszyku.
- Tworzę szkielet klas:
public class CartManager { public Product findProduct( String name ) { return null; } } public class Product { private String name; //... }
- Tworzę fragment testu jednostkowego jednostkowego:
public class CartManagerTest extends TestCase { public void testFindProduct() { CartManager cartManager = new CartManager(); Product product = cartManager .findProduct( "myProduct" ); assertNotNull( product ); } }
- Uruchamiam test: Red Bar
- Refaktoruję implementację metody (najprostsza możliwa implmentacja!):
public Product findProduct( String name ) { return new Product(); }
- Uruchamiam test: Green Bar
- Rozbudowuję test:
public void testFindProduct() { CartManager cartManager = new CartManager(); Product product = cartManager.findProduct( "myProduct" ); assertNotNull( product ); assertEquals( "myProduct" , product.getName() ); }
- Uruchamiam test: Red Bar
- Refaktoruję implementację metody (najprostsza możliwa implmentacja!):
public Product findProduct( String name ) { Product product = new Product(); product.setName( "myProduct" ); return product; }
- Uruchamiam test: Green Bar
- Refaktoruję implementację klasy:
public class CartManager { private Map<String, Product> cartMap = new HashMap<String, Product>(); public Product findProduct( String name ) { Product product = new Product(); product.setName( "myProduct" ); cartMap.put( "myProduct" , product ); return cartMap.get( "myProduct" ); } }
- Uruchamiam test: wciąż Green Bar
- 1.Refaktoruję test:
public void testFindProduct() { CartManager cartManager = new CartManager(); final String PRODUCT_NAME = "myProduct"; Product putProduct = new Product(); putProduct.setName( PRODUCT_NAME ); Map<String, Product> cartMap = new HashMap<String, Product>(); cartMap.put( PRODUCT_NAME , putProduct ); cartManager.setCartMap( cartMap ); Product product = cartManager.findProduct( PRODUCT_NAME ); assertNotNull( product ); assertEquals( PRODUCT_NAME , product.getName() ); }
- Uruchamiam test: wciąż Green Bar
- Dodaję do testu nową asercję:
public void testFindProduct() { //... assertNotNull( product ); assertEquals( PRODUCT_NAME , product.getName() ); assertSame( putProduct , product ); }
- Uruchamiam test: Red Bar
- Refaktoruję implementację metody:
public Product findProduct( String name ) { return cartMap.get( "myProduct" ); }
- Uruchamiam test: Green Bar
- 1.Refaktoruję implementację metody:
public Product findProduct( String name ) { return cartMap.get( name ); }
- Uruchamiam test: Green Bar
To wszystko jeśli chodzi o zasadniczą funkcjonalność wyszukiwania w koszyku. Zadanie domowe brzmi następująco: jeśli w koszuku nie ma produktu o danej nazwie metoda findProduct powinna rzucić wyjątek. Dodaj tę funcjonalność pracując zgodnie z TDD. Podpowiedź: aby wymusić red bar użyj metody fail().
Czyli...
Gdybym chciał wybrać jedną rzecz do zapamiętania z tego artykułu to powiedziałbym: kawałek testu, kawałek implementacji...
Friday, July 18, 2008
Antywzorce w pracy programistów: Wymyślanie koła na nowo
Zastanawiam się czy wymyślanie koła na nowo ma sens. Ktoś napisał, że jeśli ma być ono bardziej okrągłe niż dotychczasowe to tak. Trudno odmówić sensu temu stwierdzeniu. Ja rozumiem je jako udoskonalanie istniejących rzeczy. Proces udoskonalania jest oczywiście dobry i potrzebny. Jednak podczas programowania „wymyślanie koła na nowo” nabiera czasem nowego, złowieszczego charakteru.
Większość problemów, z którymi się spotkałeś została już rozwiązana. Większość bibliotek, które opracowujesz po nocach została już napisana. Większość algorytmów, które wymyślasz w przypływie twórczego geniuszu już została opublikowana. Dlaczego więc nie korzystasz z tego bogactwa wiedzy?Napisałem „większość”, uwzględniając fakt, że „są na niebie i ziemi rzeczy, o których nie śniło się filozofom".
Jeśli Twoje, z pasją tworzone, autorskie rozwiązania mają charakter edukacyjny albo zwyczajnie robisz to dla własnej satysfakcji – tym lepiej dla Ciebie. Nauczysz się czegoś ciekawego i będziesz dobrze się bawić. Lecz jeśli pracujesz i zależy Ci na wydajności – korzystaj z dorobku innych. Pamiętaj, że ludzie po prostu kochają dzielić się swoją wiedzą i doświadczeniem. Gdyby było inaczej, nie mielibyśmy w internecie żadnej grupy dyskusyjnej.
Kłopot w tym, że większość uczelni kształcących programistów zniechęca do korzystania zewnętrznych bibliotek. No, bo po co używać JGAP w programie skoro można napisać algorytm genetyczny samemu? W ciągu pięciu lat takiej metodyki nauczania studenci nabierają dziwnych nawyków nieoptymalnej pracy, a potem przyjmując studentów do pracy musimy ich tego oduczać...ech...
Większość problemów, z którymi się spotkałeś została już rozwiązana. Większość bibliotek, które opracowujesz po nocach została już napisana. Większość algorytmów, które wymyślasz w przypływie twórczego geniuszu już została opublikowana. Dlaczego więc nie korzystasz z tego bogactwa wiedzy?Napisałem „większość”, uwzględniając fakt, że „są na niebie i ziemi rzeczy, o których nie śniło się filozofom".
Jeśli Twoje, z pasją tworzone, autorskie rozwiązania mają charakter edukacyjny albo zwyczajnie robisz to dla własnej satysfakcji – tym lepiej dla Ciebie. Nauczysz się czegoś ciekawego i będziesz dobrze się bawić. Lecz jeśli pracujesz i zależy Ci na wydajności – korzystaj z dorobku innych. Pamiętaj, że ludzie po prostu kochają dzielić się swoją wiedzą i doświadczeniem. Gdyby było inaczej, nie mielibyśmy w internecie żadnej grupy dyskusyjnej.
Kłopot w tym, że większość uczelni kształcących programistów zniechęca do korzystania zewnętrznych bibliotek. No, bo po co używać JGAP w programie skoro można napisać algorytm genetyczny samemu? W ciągu pięciu lat takiej metodyki nauczania studenci nabierają dziwnych nawyków nieoptymalnej pracy, a potem przyjmując studentów do pracy musimy ich tego oduczać...ech...
Friday, July 11, 2008
Antywzorce w pracy programistów: The error is out there
Coraz częściej dochodzę do wniosku, że sposób pracy programistów nie został jeszcze całkowicie zbadany. Lawina, którą zapoczątkowali Gang of Four zbiera coraz większe żniwo. Zaczęliśmy od wzorców projektowych w tworzeniu kodu, dalej już popłynęło wzorce w projektowaniu stron www, wzorce J2EE (w innych technologiach pewnie też), wzorce integracyjne, wzorce, wzorce, wzorce...
Nie sposób zauważyć, że choć odkrywanie wzorców projektowych przebiega bardzo ekspansywnie, to jednak ogranicza się on tylko do jednej płaszczyzny: umiejętności technicznych. Nietrudno odgadnąć przyczynę tego stanu rzeczy, wszak pracujemy w konkretnej technologii, za pomocą konkretnych narzędzi i biegłość w praktyce jest gwarantem naszej atrakcyjności jako profesjonalisty w zawodzie.
Pracując z programistami w trakcie szkoleń, jako zewnętrzny konsultant, czy też jako członek zespołu, zauważam, że doskonalenie naszych umiejętności i poszukiwanie wzorców powinno odbywać się w co najmniej dwóch płaszczyznach. Pierwsza – wspomniane wcześniej umiejętności techniczne – rozwija się bardzo ekspansywnie. Druga – umiejętności nietechniczne (mniejsza teraz o nazwę) – trzeba przyznać, że trochę kuleje. Nie tak dawno pisałem o tego rodzaju umiejętnościach w artykule Metaprogramy w tworzeniu oprogramowania. Od tamtej chwili rosła we mnie chęć poszukiwania dobrych praktyk programistycznych na nietechnicznym poziomie. Owa chęć nabiera kształtu w niniejszym artykule. Postanowiłem sobie tropić wzorce w pracy programistów. Ponieważ łatwiej mi najpierw zdefiniować antywzorzec, to od nich właśnie zacznę. Będę wyróżniał postawy i schematy działania, które w moim odczuciu negatywnie wpływają na pracę programisty i jeśli to możliwe będę poszukiwał remedium.
Kilka postów wcześniej pisałem o postawie roboczo nazwanej Job Security, którą z cała pewnością można można nazwać antywzorcem. Teraz czas na drugi, który pozwoliłem sobie nazwać: The error is out there.
Niełatwo zapanować na tym schematem postępowania. Gdy poszukujemy przyczyny wadliwego działania kodu, niemal zawsze przyjmowane jest milczące założenie, że przyczyną błędu jest wadliwie działający framework, lub błąd w bibliotece, lub błąd w systemie, lub błąd współpracownika, lub działanie sił wyższych. Po kilku godzinach poszukiwań okazuje się jednak, że przyczyną zamieszania była literówka. Oczywiście wszystkie z uprzednio wymienionych błędów mogą się zdarzyć, lecz najczęściej wina leży po naszej stronie. Z jakiś powodów programiści odczuwają opór przed zaakceptowaniem faktu, że to oni mogą być przyczyną swoich niepowodzeń. A spróbuj takiemu programiście powiedzieć, że to on jest przyczyną błędu! Zdarzyło mi się parę razy narobić sobie w ten sposób wrogów, więc teraz jestem ostrożny w tego typu komentarzach.
Jak zatem sobie radzić w tego typu sytuacjach? Pytanie trzeba rozbić na dwie części. Po pierwsze, jak radzić sobie jeśli komuś pomagam oraz jak radzić sobie jeśli problem dotyczy mnie samego.
W pierwszym przypadku jest dużo prościej. Tak to już jest, że szybciej dostrzegamy czyjeś błędy niż nasze własne. Jeśli chcę komuś pomóc to unikam mówienia wprost o jego błędach – to zwyczajnie nie działa. Sprawdzają się za to niedyrektywne metafory, np. „Mój kolega też miał podobny problem i...”. Buduję krótką historyjkę o „moim koledze”, w której przekazuję wskazówki odnośnie możliwych rozwiązań. Metoda sprawdza się w 90% przypadków. Pozostałe 10% albo wymaga bardziej wyrafinowanych metod albo trafiliśmy na nieuleczalny przypadek.
Sprawy stają się bardziej skomplikowane, gdy chodzi o nas samych. Kluczem do sukcesu w tej materii jest rozwijanie umiejętności introspekcji. Wyjściowym ćwiczeniem może być tu przyjęcie założenia, że „przyczyna wadliwego działania aplikacji leży po mojej stronie”. Zdaję sobie sprawę, że reguła nie sprawdza się w 100% przypadków, ale w większości tak. Przyjęcie tego wstępnego założenia znacząco oszczędza czas. Dopiero po upewnieniu się, za pomocą możliwie obiektywnych kryteriów (warto poprosić kogoś o przeanalizowanie problemu) można przystąpić do oskarżania bibliotek i frameworków o spowodowanie kłopotów.
Friday, July 4, 2008
Iluzja O/RM
Gdy po raz pierwszy dałem się uwieść wspaniałemu konceptowi O/RM, Hibernate był w wersji 2 z kawałkiem, a o JPA nawet nie słyszałem.
Idea jest naprawdę wspaniała: raz mapujesz pomiędzy tabelami a obiektami, ba (!) nawet framework stworzy schemat bazy danych za ciebie, a potem już tylko pracujesz z obiektami - programista obiektowy swoją drogą, bazodanowiec swoją. Prawdziwy raj!
We wspomnianej wersji Hibernate'a pałętało się sporo plików xml, ale wspomagając się xdocletem można było jakoś przeżyć. Weszły anotacje i miało być jeszcze prościej, wspanialej - no, słowem obiektowa orgia.
Moim zdaniem wcale nie jest tak kolorowo. Po pierwsze dlatego, że nie możliwe jest zmapowanie O/R raz na zawsze. Baza danych wciąż o sobie przypomina. A to wyskoczy jakiś constraint i trzeba pogrzebać w bazie w poszukiwaniu przyczyn (a potem okazuje się, że to jakiś błąd mapowania:]), a to model obiektowy ulega refaktoringowi albo rozbudowie i znów należy wracać do bazy danych - wciąż wracamy do bazy danych stojąc okrakiem pomiędzy obiektami i relacjami.
Kolejną kwestią jest to, że cała idea O/RM skłania do zaniedbywania bazy danych (myślimy - nie jest moją rzeczą zajmować się bazą danych, jestem programistą obiektowym...). W związku z czym baza jest projektowana niechlujne lub (o zgrozo!) pozwala się frameworkom na zarządzanie schematem. Prowadzi to tak wielkiej kaszany w bazie danych, jak wielka kaszana tylko może być: każdy obiekt ma swoją tabele, istnieje wiele tabel zawierających po kilka wierszy ("a, bo mnie tak wyszło z mapowania..."), tabele z jedną kolumną są na porządku dziennym.
Do czego to prowadzi? Ano, bywa, że O/RM mają problem z wydajnością i czasem korzystnie jest wspomóc się jakimiś procedurami składowanymi i widokami. W takim momencie okazuje się, że praca ze schematem zarządzanym przez O/R M to gorzej niż czyściec dla duszy programisty.
W pewnym momencie rozwoju J(2)EE było paru ludzi (żeby nie wymieniać nazwisk), którzy pchnęli dalszy rozwój technologii w określonym kierunku. A społeczność za tym poszła, bo wizja była fajna. Aktualnie mam na myśli idę O/RM i całą resztę kryjąca się za wzorcem Domain Store. A przecież istnieją rozwiązania, które społeczności Javy zostały zignorowane, a które świetnie się sprawdzają w innych technologiach. Mówię rozwiązaniach, które warstwę danych organizują w okół bazy danych, a nie w okół modelu obiektowego, np: Oracle BC4J albo implementacja Active Record w Ruby on Rails
O faworyzowaniu pewnych rozwiązań świadczy choćby fakt, że do tej pory nie doczekaliśmy się popularnej i w pełni funkcjonalnej implementacji Active Record dla Javy. Myślę, że mogło by to wnieść wiele dobrego do aplikacji, które rozwijamy.
Idea jest naprawdę wspaniała: raz mapujesz pomiędzy tabelami a obiektami, ba (!) nawet framework stworzy schemat bazy danych za ciebie, a potem już tylko pracujesz z obiektami - programista obiektowy swoją drogą, bazodanowiec swoją. Prawdziwy raj!
We wspomnianej wersji Hibernate'a pałętało się sporo plików xml, ale wspomagając się xdocletem można było jakoś przeżyć. Weszły anotacje i miało być jeszcze prościej, wspanialej - no, słowem obiektowa orgia.
Moim zdaniem wcale nie jest tak kolorowo. Po pierwsze dlatego, że nie możliwe jest zmapowanie O/R raz na zawsze. Baza danych wciąż o sobie przypomina. A to wyskoczy jakiś constraint i trzeba pogrzebać w bazie w poszukiwaniu przyczyn (a potem okazuje się, że to jakiś błąd mapowania:]), a to model obiektowy ulega refaktoringowi albo rozbudowie i znów należy wracać do bazy danych - wciąż wracamy do bazy danych stojąc okrakiem pomiędzy obiektami i relacjami.
Kolejną kwestią jest to, że cała idea O/RM skłania do zaniedbywania bazy danych (myślimy - nie jest moją rzeczą zajmować się bazą danych, jestem programistą obiektowym...). W związku z czym baza jest projektowana niechlujne lub (o zgrozo!) pozwala się frameworkom na zarządzanie schematem. Prowadzi to tak wielkiej kaszany w bazie danych, jak wielka kaszana tylko może być: każdy obiekt ma swoją tabele, istnieje wiele tabel zawierających po kilka wierszy ("a, bo mnie tak wyszło z mapowania..."), tabele z jedną kolumną są na porządku dziennym.
Do czego to prowadzi? Ano, bywa, że O/RM mają problem z wydajnością i czasem korzystnie jest wspomóc się jakimiś procedurami składowanymi i widokami. W takim momencie okazuje się, że praca ze schematem zarządzanym przez O/R M to gorzej niż czyściec dla duszy programisty.
W pewnym momencie rozwoju J(2)EE było paru ludzi (żeby nie wymieniać nazwisk), którzy pchnęli dalszy rozwój technologii w określonym kierunku. A społeczność za tym poszła, bo wizja była fajna. Aktualnie mam na myśli idę O/RM i całą resztę kryjąca się za wzorcem Domain Store. A przecież istnieją rozwiązania, które społeczności Javy zostały zignorowane, a które świetnie się sprawdzają w innych technologiach. Mówię rozwiązaniach, które warstwę danych organizują w okół bazy danych, a nie w okół modelu obiektowego, np: Oracle BC4J albo implementacja Active Record w Ruby on Rails
O faworyzowaniu pewnych rozwiązań świadczy choćby fakt, że do tej pory nie doczekaliśmy się popularnej i w pełni funkcjonalnej implementacji Active Record dla Javy. Myślę, że mogło by to wnieść wiele dobrego do aplikacji, które rozwijamy.
Wednesday, June 25, 2008
Wzorzec Job Security
Prowadząc szkolenia z refaktoringu, coraz częściej natykam się na pewien specyficzny schemat zachowania. Schemat, który napawa mnie przerażeniem i kładzie cień na moich programistycznych ideałach. A było to tak...
Wykładałem pracowicie cel refaktoringu, konkretne techniki właściwe dla poszczególnych warstw i technologii i...nic jak grochem o ścianę - wszyscy uparcie twierdzili, że ich manager w życiu nie zgodzi się na poświęcenie choćby chwili na refaktoring. Przeszedłem więc do broni masowego rażenia - korzyści płynące ze stosowania refaktoringu:
A zatem, argumentowałem, potencjalnie zyskujemy najcenniejszy zasób: czas. A czas to, jak wiadomo, pieniądz! Zatem manager musi zgodzić się na rozprzestrzenianie praktyki refaktoringu...
Słuchaj, Michał - powiedział jeden z uczestników szkolenia - jeśli napiszę w czasie krótszym niż mój manager to oszacował to dostanę kolejny projekt. Dodatkowo na projekt zostanie przydzielone mniej czasu, bo już pokazałem, że potrafię pracować efektywniej. I tak z każdym kolejnym projektem mój manager wyciśnie ze mnie wszystkie soki. Jeśli dostanę 10 dni na skończenie projektu, to choćbym wyrobił się w 3, nigdy się do tego nie przyznam. Nie opłaca mi się. Poza tym, mam płacone za każdą nadgodzinę. Im dłużej pracuję, tym więcej zarabiam.
Powiedziałeś, że łatwiej jest wdrażać nowe osoby do projektu. Też mi korzyść! A jeśli nowy będzie lepszy ode mnie? Wtedy ja wylecę z roboty. Piszę mój kod tak, żebym tylko ja mógł go zrozumieć. Być może praca z JSP liczącym 2000 wierszy nie jest zbyt wygodna, ale przynajmniej wiem, że będę potrzebny. Wiem, że będę miał pracę. Refaktoring jest mi zbędny.
Szczerze mówiąc nie wiedziałem co odpowiedzieć na takie dictum...Myślałem, że gdy podzielę się tą historią, to będzie mi lepiej. Nie jest ;/
Wykładałem pracowicie cel refaktoringu, konkretne techniki właściwe dla poszczególnych warstw i technologii i...nic jak grochem o ścianę - wszyscy uparcie twierdzili, że ich manager w życiu nie zgodzi się na poświęcenie choćby chwili na refaktoring. Przeszedłem więc do broni masowego rażenia - korzyści płynące ze stosowania refaktoringu:
- Kod jest łatwiejszy w czytaniu
- Łatwiej jest dokładać nowe funkcjonalności
- Wdrożenie nowej osoby do projektu zajmuje mniej czasu
- Testowanie kodu jest łatwiejsze
- Odnajdywanie błędów trwa krócej
- Rozbudowywanie projektu zajmuje mniej czasu
A zatem, argumentowałem, potencjalnie zyskujemy najcenniejszy zasób: czas. A czas to, jak wiadomo, pieniądz! Zatem manager musi zgodzić się na rozprzestrzenianie praktyki refaktoringu...
Słuchaj, Michał - powiedział jeden z uczestników szkolenia - jeśli napiszę w czasie krótszym niż mój manager to oszacował to dostanę kolejny projekt. Dodatkowo na projekt zostanie przydzielone mniej czasu, bo już pokazałem, że potrafię pracować efektywniej. I tak z każdym kolejnym projektem mój manager wyciśnie ze mnie wszystkie soki. Jeśli dostanę 10 dni na skończenie projektu, to choćbym wyrobił się w 3, nigdy się do tego nie przyznam. Nie opłaca mi się. Poza tym, mam płacone za każdą nadgodzinę. Im dłużej pracuję, tym więcej zarabiam.
Powiedziałeś, że łatwiej jest wdrażać nowe osoby do projektu. Też mi korzyść! A jeśli nowy będzie lepszy ode mnie? Wtedy ja wylecę z roboty. Piszę mój kod tak, żebym tylko ja mógł go zrozumieć. Być może praca z JSP liczącym 2000 wierszy nie jest zbyt wygodna, ale przynajmniej wiem, że będę potrzebny. Wiem, że będę miał pracę. Refaktoring jest mi zbędny.
Szczerze mówiąc nie wiedziałem co odpowiedzieć na takie dictum...Myślałem, że gdy podzielę się tą historią, to będzie mi lepiej. Nie jest ;/
Tuesday, June 24, 2008
Metaprogramy w tworzeniu oprogramowania
Jeśli jesteś programistą albo w jakikolwiek inny sposób związany z branżą IT, to najprawdopodobniej po przeczytaniu tytułu, spodziewałeś się porcji informacji technicznych. Muszę Cię zaskoczyć, artykuł będzie o innych programach i o innym programowaniu niż sobie wyobrażasz.
Ludzie posługują się swoimi myślami w zorganizowany sposób. Dzieje się to często na poziomie nieświadomym. Gdy o czymś myślimy, w umyśle pojawiają się różnego rodzaju obrazy, odczucia czy dźwięki. Choć nie zawsze zdajemy sobie z tego sprawę, w ten właśnie sposób przetwarzamy informacje docierające z zewnątrz (i z wewnątrz).
Psycholingwistyce zawdzięczamy badania nad tą wewnętrzną organizacją codziennych doświadczeń. Okazuje się, że można wyróżnić pewne schematy, że ludzie posługują się pewnymi wzorcami zachowań, które nazwano metaprogramami. Metaprogramy zostały pogrupowane w przeciwstawne, uzupełniające się pary scenariuszy w następujący sposób:
- Unikanie – Dążenie
- Autorytet wewnętrzny – Autorytet zewnętrzny
- Podobieństwa – Różnice
- Ja – Inni
- Informacje szczegółowe – Informacje globalne
- Proaktywne – Reaktywne
- Opcje – Procedury
Dla osoby skoncentrowanej na unikaniu, bodźcem do działania będzie chęć uniknięcia niepożądanych sytuacji. Przeciwnie, dla osoby posługującej się metaprogramem Dążenie, ważniejsze będzie osiągnięcie wyznaczonego celu. Czytelników zainteresowanych dokładnym poznaniem metaprogramów odsyłam do literatury.
Preferowane metaprogramy
W praktyce nigdy nie jest tak, aby dany scenariusz np. Unikanie występował w czystej formie. Jest tak przede wszystkim dlatego, że procesy myślowe są w swej naturze zbyt skomplikowane (i jeszcze wiele jest do odkrycia), by opisać je za pomocą tak prostego modelu jakim są metaprogramy. Koncept metaprogramów należy traktować zatem jako pewne przybliżenie rzeczywistości o ograniczonym zakresie stosowalności.
Używanie metaprogramu jest zależne od kontekstu (kontekstualizm), środowiska w którym znajduje się człowiek. Ktoś na co dzień skoncentrowany na Dążeniu może radykalnie zmienić sposób myślenia, gdy ucieka przed goniącym go psem – wtedy najprawdopodobniej skupi się na uniknięciu niebezpieczeństwa, bez znaczenia w jaki sposób.
Bardzo istotne jest to, że metaprogramy nie podlegają ewaluacji. Żaden z nich nie jest lepszy lub gorszy – są inne. Jedyne co można powiedzieć to, że dany scenariusz może być mniej lub bardziej użyteczny w określonej sytuacji. Zadaniem artykułu jest, przede wszystkim, pobudzenie do refleksji nad własnym stylem pracy.
Choć obserwując zachowania ludzi, można wskazać pewne przejawy każdego z metaprogramów to jednak poszczególne osoby mają osobiste preferencje. Najczęściej 1 do 3 metaprogramów dominuje, pozostałe pojawiają się sporadycznie. W dalszej części zastanowimy się, które z metaprogramów są najistotniejsze w pracy programisty.
Zbieranie wymagań
Zbieranie wymagań oraz modelowanie systemu są czynnościami o tyle ważnymi, że kierunkują dalsze prace zespołu. Prace nad projektem rozpoczynają się (powinny się rozpoczynać) od stworzenia jego wizji. Wizja, w postaci metafory, jest metacelem, do którego zmierzać będzie projekt w kolejnych fazach rozwoju. Dalej wyłania się zbiór wymagań, zestaw procesów, w których może brać udział użytkownik. Pojawia luźny koncept rozwiązania i będzie uszczegóławiany w dalszych krokach.
W opisanym wyżej procesie projektowania zauważamy, że prace odbywają się na poziomie ogólnym. Programiści/projektanci wykazują w tym miejscu tendencję do skupiania się na konkretnym rozwiązaniu. Podczas rozmowy z potencjalnym użytkownikiem, od którego należy zebrać wymagania, deweloper stara się podążać za tokiem myślowym rozmówcy. Jednocześnie zastanawia się, czy i jak konkretne wymaganie zostanie zrealizowane. Myślenie o rozwiązaniu jest jak najbardziej w porządku tyle, że nie na to jest miejsce podczas zbierania wymagań, gdy należy się skoncentrować na zrozumieniu wyobrażeń użytkownika o sposobie pracy z przyszłym narzędziem. Z tego względu zbieranie wymagań warto przeprowadzać w sesjach, np.: godzinę rozmowy z użytkownikiem, a następnie pół godziny na analizę wymagań i formułowanie dodatkowych pytań.
W artykule Klient, który wie, czego chce rozważałem różnice w sposobie myślenia analityka i klienta. Głównym wnioskiem było to, że klienci jednak wiedzą, czego chcą. Opisują to jednak w postaci procesów, natomiast analityk widzi system jako strukturę. Podążając za procesem łatwiej dokonywać w nim zmian. Z kolei zmiany wprowadzane w strukturze wymagają przeanalizowania całej koncepcji od nowa. Podczas zbierania wymagań klient często zastanawia się nad pożądanym sposobem pracy. Próbuje różnych alternatywnych przebiegów tego samego procesu i oczekuje od analityka pomocy w wyborze najlepszego rozwiązania. Jeśli analityk nie podąża w procesie za klientem, lecz percypuje system jako strukturę, to ma nie lada kłopot. Alternatywne ścieżki procesu klienta zazwyczaj mają istotny wpływ na domniemaną strukturę systemu i/lub implementację.
Dochodzimy do kolejnego, istotnego w pracy programisty, metaprogramu: Opcje – Procedury. Najczęściej klient chce próbować różnych możliwości – jest nastawiony na opcje. Analityk powinien wyjść naprzeciw tym oczekiwaniom. Należy przypomnieć fakt, że nastawienie na opcje może nie być głównym metaprogramem klienta. Jednak w kontekście zbierania wymagań, gdy zastanawia się on nad sposobem pracy z narzędziem i analizuje różne procesy, najczęściej chce mieć możliwość wybrania najlepszego rozwiązania spośród dostępnych.
Podsumowując część o zbieraniu wymagań stwierdzamy, że w tym kontekście pracy programisty ważne jest nastawienie na Ogół oraz na Opcje. Te sposoby myślenia pozwalają pozostać na odpowiednim poziomie abstrakcji i skupić się na wizji i celu istnienia systemu zamiast brnąć w konkretne technologie i rozwiązania tylko po to, aby w następstwie późniejszych decyzji w pośpiechu się z nich wycofywać.
Programowanie
Po zebraniu wymagań i zaplanowaniu prac przychodzi czas na implementację. W chwili obecnej role projektanta oraz programisty przenikają w projekcie. Myślę, że to dobrze, gdyż można w pełni wykorzystać potencjał tkwiący w programistach. W tej sytuacji deweloperzy dostają pewne wytyczne z projektem systemu i mają dość dużą dowolność w implementowaniu poszczególnych klas oraz metod.
Implementacja złożonego systemu informatycznego, gdzie współpracuje ze sobą wiele niezależnych bytów, jest skomplikowanym zadaniem. Na tym etapie programujemy już konkretne zachowania i procesy. Od programisty oczekujemy, że będzie potrafił uzasadnić wybór tego, a nie innego rozwiązania. Dodatkowo należy przestrzegać obowiązujących w zespole konwencji kodowania, zasad projektowania, wytycznych pisania testów, itp. Nie ma tu miejsca na swobodną twórczość albo raczej ma ona miejsce drugorzędne. Ważniejsze jest przestrzeganie określonych zasad – procedur. Ujawnia się nam kolejny scenariusz pomocny programiście: Procedury. Osoba, sprawnie posługująca się procedurami, rozważa rzeczywistość jako ciąg logicznych następstw, gdzie każde zdarzenie ma swoją przyczynę oraz konsekwencje. Intuicyjnie czujemy, że Procedury to jeden największych sprzymierzeńców programistów. Możemy być dumni z faktu, że wykorzystujemy metaprogram do tworzenia wspaniałego oprogramowania.
Warto jeszcze poruszyć jeszcze jeden aspekt programowania, istotny w kontekście rozważania metaprogramów. Mowa o abstrahowaniu. Języki obiektowe dają sposobność budowania złożonych zależności pomiędzy klasami dzięki np. dziedziczeniu, polimorfizmowi, interfejsom. Możliwości te, aż same zachęcają do ich korzystania. Istota kwestii leży w sposobie korzystania z tych udogodnień. Gdy programista implementuje daną funkcjonalność ma tendencję do tworzenia całej gamy abstrakcyjnych bytów „na wyrost”. Efekt jest taki, że w projekcie każda klasa implementuje specyficzny interfejs (nie używany nigdzie indziej) oraz posiada, do niczego nie potrzebną, klasę abstrakcyjną. Z kolei podczas używania danych klas i tak wszędzie następuje rzutowanie na obiekty konkretne. Przyczyną takiego tworzenia kodu jest „zachłyśnięcie się” paradygmatem reużywalności i elastyczności komponentów. Oczywiście paradygmat ten jest jak najbardziej słuszny, lecz sposób jego egzekwowania już nie. Błąd programisty polega na próbie zaprojektowanie stworzenia maksymalnie rozszerzalnego kodu i „zapomina” że każde rozwiązanie ma ściśle określone granice stosowalności. Programista próbuje stworzyć komponenty możliwe do zastosowania wszędzie (Golden Hammer). Popatrzmy na poniższy kod:
public interface Problem {
//...
}
public interface Solution {
//...
}
public interface UniversalProblemSolver {
public Solution solve( Problem problem );
}
Właściwie każda klasa mogłaby implementować interfejs UniversalProblemSolver, prawda? Gdy tworzymy kod, który ma dostarczać określoną funkcjonalność i koncentrujemy się przede wszystkim na jego uniwersalności, zamiast na konkretnym zadaniu które ma wykonać, popadamy w opisaną wyżej pułapkę. W takiej sytuacji myślimy poprzez Ogół i tworząc abstrakcyjne byty, zmierzamy do celu wyjątkowo krętą ścieżką.
Optymalne programowanie wymaga podejścia od strony Szczegółu. Najpierw tworzymy konkretne rozwiązanie implementujące żądaną funkcjonalność. Jeśli w trakcie tworzenia kodu zajdzie potrzeba abstrahowania: wydzielenia hierarchii dziedziczenia, interfejsów – refaktorujemy kod. Praca odbywa się zatem od Szczegółu do Ogółu – w odwrotnym kierunku niż w przypadku zbierania wymagań i modelowania systemu. Ten styl programowania wymaga od deweloperów wewnętrznej samodyscypliny. Warto skorzystać z technik programowania np. Test-Driven Development, które wspomagają ten styl pracy. TDD, dzięki filozofii pisania testu funkcjonalności przed jej implementacją, zabezpiecza przed nadmiarowym „rozdmuchiwaniem” klas i dokładaniem kodu, być może użytecznego, lecz zbędnego z punktu widzenia tworzonego systemu.
Przenoszenie metaprogramów
Powyżej wyróżniłem dwa konteksty pracy programisty, w których pożądane jest posługiwanie się odmiennymi scenariuszami metaprogramów Ogół – Szczegół oraz Opcje – Procedury. Ta właśnie potrzeba przełączania się pomiędzy różnymi scenariuszami rodzi wiele kłopotów i frustracji. Jest tak przeważnie dla tego, że „uruchamianie” odpowiedniego metaprogramu odbywa się w sposób nieświadomy. Drugą przyczyną, jak na ironię, jest zdolność do uczenia się. Przypuśćmy, że ktoś uczy się programowania. Po jakimś czasie wykształca sobie pewien sposób myślenia i sprawnie posługuje się scenariuszami Procedury oraz Szczegół. W umyśle człowieka rodzi się skrót myślowy: jeśli TO zadziałało w TYM przypadku, z pewnością zadziała również w TAMTYM. Ów człowiek, za pomocą metaprogramu, dobrze działającego w jednym kontekście (praca) próbuje wykonywać działanie w zupełnie innym kontekście (np. relacje międzyludzkie). To zjawisko może prowadzić do niepożądanych skutków. Praca nad własnymi metaprogramami uwrażliwia nas na podobne sytuacje i uczy efektywnego funkcjonowania w różnych kontekstach.
Korzyści
Najważniejszą, moim zdaniem, korzyścią ze znajomości i rozwijania określonych metaprogramów jest rozszerzenie spektrum możliwych reakcji na sytuacje pojawiające się podczas prac nad projektem. Umiejętność posługiwania sposobami myślenia innymi niż nasze własne sprawia, że efektywniej współpracujemy z klientami, użytkownikami oraz z innymi członkami zespołu. Poniżej wymieniam dodatkowe korzyści:
- pomoc w formowaniu zespołu projektowego
- wyznacznik dla osób rekrutujących programistów
- skrócenie czasu zbierania wymagań
- poprawa komunikacji w zespole
- pomoc podczas projektowania ścieżki rozwoju dla programistów
Podsumowanie
W artykule wyróżniłem metaprogramy Ogół – Szczegół oraz Opcje – Procedury jako bardzo istotne w pracy programisty. Zdaję sobie sprawę, że istnieje wiele punktów w procesie rozwoju oprogramowania, które nie zostały tu wspomniane. W obszarach tych również korzystamy ze specyficznych metaprogramów i wiedza o nich będzie nieocenioną pomocą. Dalszą eksplorację tego zagadnienia rezerwuję sobie na najbliższą przyszłość. Warto wskazać czego potrzeba opracowaniu tego typu, aby stanowiło rzetelną pomoc w pracy dewelopera:
- kompletny opis procesu wytwarzania oprogramowania z punktu widzenia wykorzystywanych metaprogramów,
- opis efektywnych technik pracy na każdym z etapów,
- zestaw ćwiczeń pozwalających rozwijać pożądane metaprogramy.
Każdy krok w kierunku rozwoju własnego warsztatu pracy uświadamia, że istnieje coś poza technologią, coś co porządkuje poszczególne umiejętności i pozwala korzystać z ich jeszcze efektywniej. Odkrywanie tych zasobów jest fascynującą podróżą ku doskonałości.
Subscribe to:
Posts (Atom)